How Mid-SaaS Companies Scale QA Without Slowing Releases
Summarize With:

Harsh Goel
Most SaaS teams think they have a QA speed problem.
So they reach for the obvious fixes: more testers, more automation, more pressure at the end of the sprint.
But those fixes rarely solve the real issue.
Problems arise because the entire QA architecture gets broken as the product grows, and instead of scaling the existing system, it should be redesigned as an early, risk-focused, maintainable system that builds confidence throughout the development cycle.
This article breaks down how to spot a problematic QA system, how to apply fixes, and how to build a scalable QA system that never fails.
How to Spot Issues in Your QA Model
Before any fix makes sense, you need an honest picture of your system. When ThinkSys audits a QA architecture, these are the three numbers pulled first, because they reveal more than any coverage report.
- Test Maintenance Ratio: What percentage of QA time is spent maintaining existing tests versus building new coverage?
- Flaky Test Rate: What percentage of CI failures are non-deterministic or unreliable?
- Exploratory Testing Frequency: When did your team last run structured exploratory testing on a high-risk workflow?
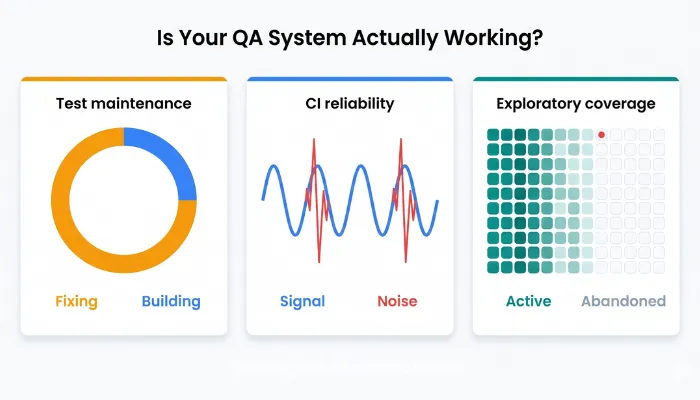
These three metrics reveal whether your QA system is sustainable, trustworthy, and capable of discovering unknown risks.
| QA Metrics | Healthy | Borderline | Critical |
| Test Maintenance Ratio | < 30% of QA time spent maintaining existing tests | 30%–50% of QA time spent maintaining existing tests | > 50% of QA time spent maintaining existing tests |
| Flaky Test Rate | < 5% of CI failures are flaky or non-deterministic | 5%–15% of CI failures are flaky or non-deterministic | > 15% of CI failures are flaky or non-deterministic |
| Exploratory Testing Frequency | Within the last 2 weeks | 2–6 weeks ago | More than 6 weeks ago |
If any one of these falls in the critical range, adding more people or more automation will make the problem worse.
The four sections below show you what to do instead.
Fix 1: Bring QA Before the Code Is Written
When QA sits at the end of the sprint, it absorbs everything that was unclear upstream, ambiguous requirements, untestable code, integration assumptions nobody documented, all at once, right before the release window.
This way, the QA team just receives the work too late to do anything useful with it.
Most engineering teams already run one to three QA engineers per ten developers. That ratio is not the issue. The batching is.
For example, one marketplace ran 120 QA resources across eight product lines and still spent more than 120 days per release cycle. More people produced more scripts.
More scripts produced more maintenance.
Nobody changed when QA entered the process.
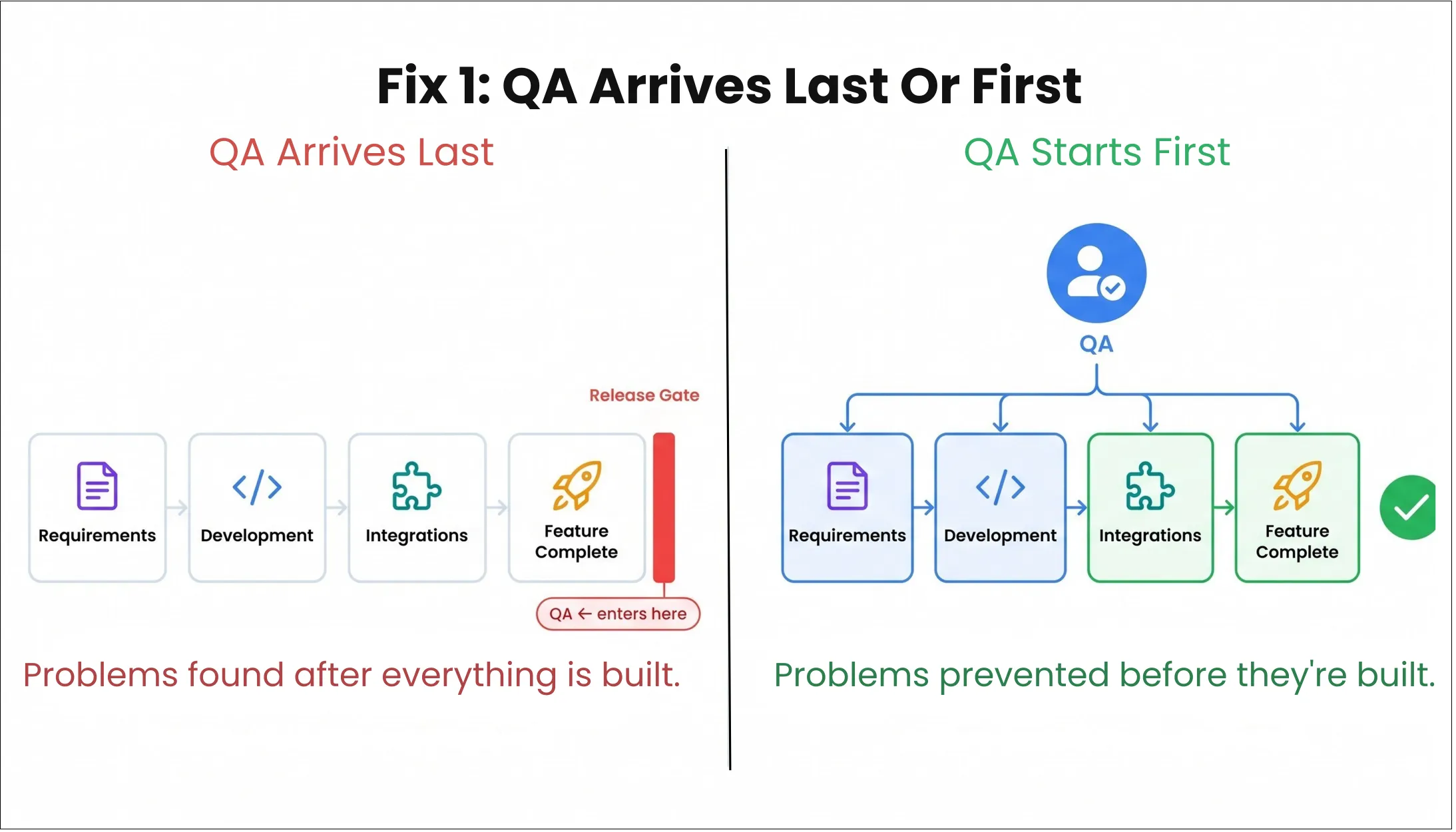
What shifting QA upstream actually looks like:
When ThinkSys restructures QA ownership for a team, it makes sure QA engineers are included in the conversation.
Here is what that means in practice:
- QA attends sprint planning and backlog refinement, not to estimate tickets, but to flag testability issues before implementation begins. A requirement that is hard to test usually signals something ambiguous in the spec itself.
- Acceptance criteria get QA input before they are finalized, so the definition of "done" already reflects what a real quality check requires, not just what the developer considers complete.
- Risk mapping happens at the feature level, not the ticket level. QA engineers identify which parts of a feature carry the highest chance of unexpected failure before a single line of code is written.
- QA owns a product area; instead of picking up whatever ticket appears. QA engineers develop deep familiarity with specific workflows, which means they arrive at testing already knowing the risk surface.
The practical signal that this is working: QA stops being the last item on the sprint board and starts being the first conversation in the refinement meeting. Releases stop being delayed by late-discovered ambiguity because that ambiguity was resolved three weeks earlier.
Fix 2: Build a Test Suite That Stays Cheap to Own
Research from Momentic found that 60 to 80 percent of automation effort in scaling teams goes to maintaining existing tests, not writing new ones.
In practice, that is roughly three hours of repair work for every hour of new coverage.
A four-person QA team spending 15 to 20 hours a week on maintenance has almost no real capacity left to extend coverage.
Add a fifth person, and you do not unlock better quality; you add someone who inherits the same brittle suite and the same burden.
The most common trigger is a false failure nobody planned for.
A button label changes from "Submit Order" to "Place Order." The flow still works. The customer experience is intact.
But five tests fail because they were written against copy and selectors rather than the behavior that actually matters.
Multiply that across a growing product and a growing team, and the suite becomes expensive without becoming more useful.

How ThinkSys rebuilds suites for long-term maintainability:
- Tests are written against behavior, not implementation details. The test validates that the checkout flow completes successfully, not that a specific button with a specific label exists at a specific DOM location.
- Page object abstractions absorb UI change in one place when a component gets refactored. As a result, one file updates instead of thirty tests breaking. This single architectural decision typically reduces UI-related test failures by more than half.
- Data factories separate the test setup from UI state, and tests stop depending on fragile pre-conditions manually constructed through the interface, which eliminates an entire category of flaky failures.
- Smoke checks are kept strictly separate from regression; the team stops confusing "we confirmed the known path works" with "we tested this feature." Both have a role. They are not the same activity.
- Test health is reviewed on a regular cadence, not just when something breaks. ThinkSys builds a monthly review into the QA process where tests that have not caught a real defect in 90 days are either retired or downgraded in priority.
ThinkSys clients typically see test maintenance overhead drop by 40 to 60 percent after this architectural change. That freed capacity goes directly into new coverage on the workflows that actually carry business risk, not into keeping a brittle legacy suite alive.
A useful self-check before moving on: of the last ten CI failures your team investigated, how many were real product defects versus broken test infrastructure?
If more than three were infrastructure failures, the suite is consuming more capacity than it is protecting.
Fix 3: Make Your Regression Suite a Decision Tool
Every release adds tests. Almost nobody removes them, downgrades them, or asks whether they still deserve to run on every commit.
Over time, the suite becomes a historical record of everything the team has ever worried about. That is an accumulation.
If your full suite takes four and a half hours today, it will take six hours next quarter and eight hours the quarter after that. Teams start skipping full runs, delaying them, or pushing them to the edge of the release cycle, where failures are most expensive to act on.
This kind of test debt can slow releases by 60 percent despite having a solid regression strategy.

How ThinkSys builds a tiered regression system that actually works:
- A critical path tier runs on every commit. A small, curated set of tests covering the flows with the highest revenue risk and customer impact. This tier must finish in under 15 minutes. If it does not, it gets trimmed until it does.
- A broader regression tier runs on a defined cadence, typically nightly or per-branch, covering the wider product surface without blocking every merge.
- An exhaustive tier runs pre-release only. The full suite, edge cases, and integration checks that do not need to run on every small change, but must pass before anything ships to production.
- Tier assignment is a product and engineering decision, not just a QA decision. ThinkSys facilitates a risk mapping session with product and engineering leads to identify which flows carry the most business consequence if they fail. QA cannot make that call alone, and it should not try.
- The suite is actively pruned, not just grown. Tests that have not caught a real defect in a defined window are reviewed. Redundant tests are removed. The goal is a suite that is small enough to trust and fast enough to use.
The test that tells you whether this work has been done: can your team name the twenty tests that would justify holding a release if they failed? If not, you do not have a tiered regression strategy.
Fix 4: Build a System That Catches What Nobody Thought to Test
CrowdStrike failed despite having tests, validators, and multiple review layers.
On July 19, 2024, 8.5 million Windows machines crashed because the sensor logic expected 20 input fields while the content update contained 21. Testing had used wildcard matching on the 21st field instead of production-realistic values.
Nobody had built a check for that exact condition because nobody had fully imagined it first.
Automated tests verify known conditions. They confirm that the paths you anticipated still behave the way you expect.
They are completely blind to the paths you missed, and on a complex, fast-moving product, the paths you missed are where the serious defects live.
This is also why high coverage numbers coexist with low confidence.
Coverage tells you how much of the product has been touched by a test. It does not tell you whether those tests cover the failure modes most likely to hurt the business.
Teams reporting significant flakiness grew from 10 percent in 2022 to 26 percent in 2025, a sign that suites are being extended without the discipline to keep them trustworthy.
Once the suite becomes noisy, the team stops learning from it, manual testing creeps back in, and the bottleneck returns in a new form.

How ThinkSys builds structured exploratory testing into the release process:
- ThinkSys builds dedicated exploratory testing time into the regular release cadence, treated as a first-class quality activity with the same priority as automation work.
- Each session has a specific charter, not "test the checkout flow" but "test the subscription downgrade flow during an active billing cycle." A bounded scope, a time limit (typically 90 minutes to two hours), and a clear question the session is trying to answer.
- Sessions are assigned to the highest-risk workflows. Determined by the same risk mapping that drives regression tier assignment, so exploratory effort concentrates on where automated checks are most likely to have blind spots.
- Findings are documented and acted on, not just bugs filed, but notes on what felt risky, what looked unknown, and what conditions were not covered by existing automation. These feed directly into the next sprint's coverage work.
- Exploratory results inform automation priorities. When a session surfaces a failure mode nobody anticipated, the immediate question is whether that condition can now be automated. Often it can. The exploratory session is how you find out what to build next.
Without this discipline, the team confuses automation with completeness. That is how serious defects stay invisible until production gives them a name.
Why These Four Fixes Matter More Right Now
All four of these changes were worth making before AI-assisted development. AI has simply made the cost of not making them higher.
Research from METR found that developers using AI coding tools believed they were 20 percent faster while actually being 19 percent slower, a 39-point perception gap. Perceived speed changes behavior before actual system performance catches up. Teams merge, and more volume enters the pipeline.
At the same time, CodeRabbit found that AI-generated code produced 1.7 times more issues than human-written code, including 2.25 times more algorithmic and business logic errors. Clearly, apart from absorbing more code, the pipeline is absorbing more subtle defects too.
A QA architecture with any of the four problems above cannot absorb that combination. The same suite that was already expensive to maintain is suddenly expected to catch a broader, noisier class of failure, faster, with less time to investigate.
This is why so many teams feel as if QA got slower right when development got faster. Development started producing change faster than the quality system could responsibly absorb it.
How ThinkSys Helps Mid-SaaS Teams Build Scalable QA Systems
ThinkSys specializes in QA architecture for mid-sized SaaS companies, teams that have outgrown their original quality system but have not yet rebuilt it for the product they are running today.
The starting point is a 30-minute QA architecture audit. We pull your three diagnostic numbers, identify which of the four structural gaps are active in your system, and give you a clear picture of what the fix looks like, before you spend another sprint in the same bottleneck.