Non-Functional Testing Requirements for Enterprise Software
Summarize With:

Harsh Goel
Non-functional failures don’t show up as bugs, they show up as revenue loss, SLA breaches, and customer churn.
A slow checkout during peak traffic. A delayed payroll run. A security vulnerability exposed during an audit.
These aren’t QA issues. These are business risks.
Software testing is often assumed to focus only on functionality, ensuring that applications work as expected and fulfill their core purpose.
While functional correctness is essential, it represents only a part of what determines whether enterprise software succeeds in real-world conditions.
Security, performance, scalability, usability, reliability, and portability are equally critical, especially for systems that support large user bases and business-critical workflows.
The impact of getting these wrong is significant (average unplanned IT downtime costs around $14,000 per minute, rising to nearly $24,000 per minute for large enterprises).
The difference between functional and non-functional testing lies in the outcome they are designed to validate.
For example, functional testing may verify that a payroll system correctly calculates salaries.
In contrast, non-functional testing ensures that the same system can process payroll for up to 50,000 employees within 20 minutes at peak load, with zero data loss tolerance and 99.95% accuracy.
This distinction makes non-functional requirements measurable, testable, and directly tied to business risk. For enterprise platforms handling thousands of concurrent users, distributed systems, and mission-critical workflows, non-functional testing is no longer optional.It is the difference between controlled scale and operational failure.
Yet many engineering teams under-test non-functional scenarios or treat them as a late-stage activity, leading to production surprises that are expensive to fix and difficult to recover from.
This guide breaks down how enterprise teams can define, design, and execute non-functional testing requirements across performance, resilience, security, and observability, so systems don’t just work, they perform under real-world pressure.
Who This Guide Is For
- CTOs and VP Engineering responsible for system scalability, uptime, and risk mitigation
- A Directors and Heads of Quality ensuring release stability across complex systems
- Engineering teams managing high-scale enterprise or SaaS platforms
- Product teams owning revenue-critical workflows like checkout, payments, or financial operations
- Teams preparing for high-traffic events such as sales, launches, or seasonal spikes
Why Non-Functional Failures Become Business Failures
Non-functional gaps don’t fail silently. They compound into measurable business damage:
- Performance issues: Lost conversions and user churn
- Downtime: Direct revenue loss and SLA penalties
- Security gaps: Compliance violations and reputational damage
- Poor observability: Delayed incident response and longer outages
For enterprise systems, even minor inefficiencies at scale can translate into significant operational and financial impact.
The question is no longer “Does the system work?” but “Does it work reliably under real-world pressure?”
What is Enterprise Non-Functional Testing?
Non-functional testing involves validating how effectively and efficiently the system performs, instead of just what it usually does. The requirements for enterprise non-functional testing emerge from interviews with business stakeholders, operations teams, security officers, and end users.
These requirements then get translated into measurable acceptance criteria before development begins. If you skip or shorthand this process, you may pay the penalty when production deployments expose security or performance gaps that should have been anticipated months earlier.
These requirements can also be identified by asking questions such as:
- Can the system sustain end-of-month or seasonal peaks without degrading business operations?
- Does it recover gracefully when a core database node fails mid-transaction?
- Are PII and financial records protected when the platform is under attack?
- Can your operations team see and diagnose issues quickly enough to keep outages below your SLA?
In addition to that, the following is a quick comparison matrix between functional and non-functional testing requirements for better understanding:
| Aspect | Functional Requirements | Non-Functional Requirements |
| Focus | What features do. | How well they behave. |
| Example | The user can approve a purchase order. | Approval completes in ≤ 2 seconds for 5,000 concurrent approvers. |
| Output | Pass/fail per scenario. | Measured KPIs VS thresholds. |
| Failure impact | Feature unusable. | The entire business is slowed or blocked. |
Why Non-Functional Testing Holds Immense Value for Enterprise Software?
Before diving into the testing requirements, you need to know why non-functional testing is crucial for your enterprise software. The following statistics will help you get a clearer picture.
- A recent global study of large enterprises estimates that unplanned digital downtime costs around USD 400 billion annually, or about 9% of profits. Individual companies lose an average of 200 million USD per year from IT failures and outages.
- 56% of downtime incidents were caused by security issues, while 44% came from application or infrastructure problems such as software failures and misconfigurations.
- Companies that suffer IT failures from cyberattacks or self-inflicted shutdowns typically see their stock price drop by an average of 2.5% and take 79 days to recover.
Furthermore, non-functional risk in enterprise environments clusters around a few recurring themes that are elaborated below:
- Concurrency with Cross-Module Workflows
Enterprise platforms face thousands of simultaneous transactions interacting across interconnected modules. A seemingly simple flow starting at order entry and moving to inventory reservation, pricing, invoicing, and ending at GL posting may trigger dozens of downstream processes, touch several databases, and depend on distributed services. Even a single unoptimized step can affect the system, creating slowdown and operational gridlocks. - Data Volume and Data Gravity
Every enterprise software accumulates numerous datasets constantly, which often span tens or hundreds of millions of records. Query engines, reporting tools, and batch processors must execute complex joins, aggregations, and calculations without degrading response times, even when retention policies preserve historical depth for compliance. - Integrations
If there is one thing constant about enterprise software, it's that it never operates in isolation. Critical workflows depend on integrations. Any integration latency or authentication issues reverberate upstream, converting localized issues into system-wide productivity failures that users never forgive. - Regulation, Audit, and Traceability
Performance or security weaknesses inside enterprise programs trigger legal issues and compliance penalties. When systems handling payroll, taxation, or financial posting slow down or break, the consequences escalate beyond technology and into regulatory risk with significant financial impact.
Pillars of Non-Functional Testing for Enterprise Software
Non-functional testing forms the structural framework that makes enterprise systems trustworthy under real-world pressure. When broken down, the discipline naturally clusters into six pillars that capture the full spectrum of operational risk.
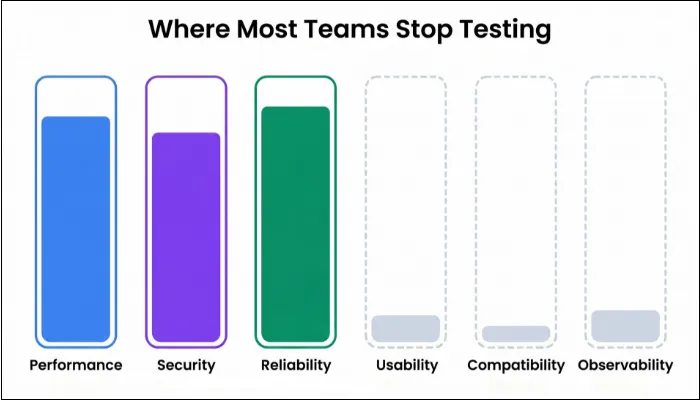
- Performance and Scalability Testing: Your actions must complete within time while the system elastically grows with user volumes. Load testing validates peak-hour performance, stress reveals breaking points, and endurance detects slow degradation. These baselines become your production SLOs and alert triggers moving forward.
- Reliability, Availability, and Resilience Testing: When databases crash or nodes fail, graceful recovery matters more than perfection. Deliberately injecting failures into your staging environment and measuring RTO/RPO compliance is a part of this testing.
- Security and Compliance Testing: Before launching, you will probe for vulnerabilities, test access controls rigorously, and validate that encryption is protecting sensitive data. Compliance audits verify you’re not accidentally breaching GDPR, HIPAA, PCI-DSS, or sector-specific regulations that impose fines if violated. Penetration testing simulates what attackers would attempt against your app and data.
- Usability and Accessibility Testing: Diverse user populations use your system regularly. Here, the task completion rates showcase whether your workflows are intuitive, and SUS scores measure satisfaction objectively.
- Compatibility Testing: Your application will run across desktop browsers, mobile devices, legacy systems, corporate VPNs, and integrations with dozens of third-party platforms simultaneously. Testing across this sprawl prevents silent failures that only surface when specific user segments encounter incompatibilities.
- Observability Testing: Comprehensive logging, metrics, and distributed tracing answer “what failed and why” in minutes, not hours. Your operational runbooks should be validated repeatedly, so SRE practices function reliably when incidents occur and the stakes run high.
Enterprise Non-Functional Testing Types and Requirements
As non-functional testing focuses more on software quality than functionality, the testing types and requirements differ from those of functional testing. This section explains all about different NFT types and requirements.
1. Performance Testing
Performance testing is where you find out whether your enterprise platform behaves as a traffic jam waiting to happen. Here, you’re not just measuring speed but validating how the entire program behaves when real business pressure shows up.
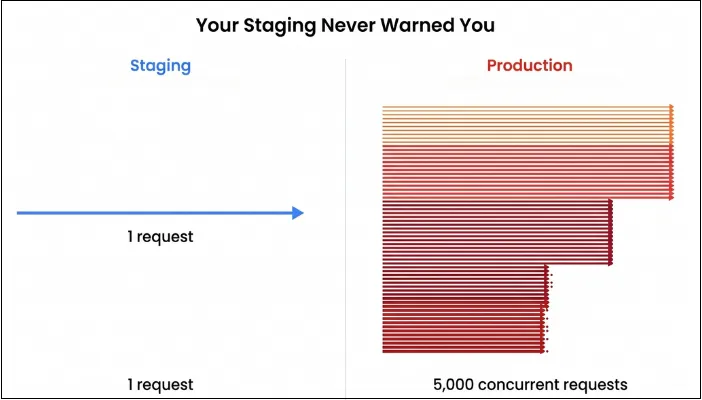
In addition, performance testing checks how fast, stable, and scalable your system is under realistic and extreme workloads. With performance testing, you’re going to answer questions such as:
- How does creating a sales order behave when 3,000 reps hammer it at once?
- What happens to the month-end close when overnight jobs collide with heavy daytime access?
- Does auto-scaling actually kick in before users feel pain?
Example:
Consider an enterprise workflow such as order-to-cash in a retail distribution system.
A single transaction may involve:
- Order creation
- Inventory reservation
- Pricing engine calculations
- Invoice generation
- Financial posting
Under peak load, thousands of such workflows execute simultaneously. Even a single latency spike or unoptimized step can slow down the entire chain, impacting business operations and transaction throughput.
Types of Performance Testing
| Type | Primary question | Typical enterprise example |
| Load testing | Can we handle the expected peak traffic? | Payroll runs for 20000 employees with concurrent self-service access. |
| Stress testing | Where does it break, and how? | Doubling peak order volume during a promotion. |
| Spike testing | Can we survive sudden bursts? | 10x HR portal logins after bonus letters go live. |
| Endurance/soak testing | Does it degrade over long durations? | 48h continuous planning + MRP overnight runs. |
| Volume testing | What happens when data size explodes? | Reporting on 7 years of ledger data and archived HR records. |
| Scalability testing | How do performance and cost change as we add capacity? | Adding more app pods / VMs to support a new region or business unit. |
Even though there are multiple performance testing types, you won’t always need every type for every release. However, if you only ever run one peak load test, you’re flying blind. The best approach is to use the right type as per the demand for the best outcome.
Requirements to Understand Before Designing Test Cases
For enterprise software, performance tests fail more often because of bad prerequisites than bad scripts. With that in mind, understanding the requirements helps in extracting the right results from tests.
- Clear NFRs: Not fast enough, but P95 ≤ 2 seconds for Create Sales Order at 2,000 concurrent users; error rate ≤ 0.5%, CPU ≤ 75% on app nodes.
- Business Workload Definition: Top 10-20 transactions by volume and business criticality, and include read/write mix, batch vs. interactive, and integration calls.
- Environment that Resembles Production: Similar topology (nodes, DB type, cache, queues), realistic network (latency, bandwidth constraints), and same key config (thread pools, connection pools, JVM/CLR settings, auto-scaling rules).
- Instrumentation in Place: You need to measure application metrics, DB monitoring, OS metrics, logs, and tracing wired before you hit run.
How to Design a Performance Test
- Pick a Business Scenario: Example: Order to cash for retail distribution rather than POST /api/order. Include the natural steps: create order → reserve stock → apply pricing → confirm shipment → post invoice.
- Map the Technical Path: For that scenario, list which microservices, DBs, queues, and external systems are involved. Note pricing engine, inventory service, tax API, and other latency-sensitive hops.
- Define KPIs and Pass/Fail Criteria: Make sure to measure response time, throughput, error rate, and resource ceilings.
- Model Realistic Behavior: Here, you need to think about time, flow, and concurrency of the users.
- Wire in Monitoring Stories: For every KPI, decide where you’ll read it: APM, DB dashboard, OS metrics, logs. Define what a healthy curve looks like before you run.
- Run, Observe, and Iterate: Expect the first run to be noisy, where you may need to fix script issues, adjust think-times, and re-run until the test represents the real world. Only then do you treat results as evidence.
Sample Performance Test Case
| ID | Scenario | Inputs & Load Profile | Expected Outcome |
| PT-01 | HR login surge at 10:00 AM. | 8,000 concurrent logins within 5 minutes. | P95 login ≤ 2s, CPU ≤ 70%, auth service error rate < 1%. |
| PT-02 | Month-end financial close. | 500 finance users posting batches and overnight jobs. | No job overrun > 10%, DB locks within acceptable bounds without deadlocks. |
| PT-03 | Stress: double peak order volume. | 2x regular sales orders for 90 minutes. | Degradation is graceful with clear saturation point identification and without data corruption. |
| PT-04 | 24-hour soak for manufacturing planning. | Continuous workload of planners + batch schedules. | No memory leaks, GC thrashing, and increasing error trend. |
2. Resilience, Reliability, and Availability Testing
Reliability testing involves asking a simple yet significant question: Can your system stay alive when the environment refuses to cooperate? Availability testing, following up with a bit harsher question: can your users depend on your platform every time they need it, without relying on luck?
Then comes resilience testing, which completes the triad by challenging the system to prove whether it bends or breaks when failures appear without prior warning.
These tests determine whether your software behaves like a dependable program or a fragile collection of services pretending to be a platform.
Example:
During a high-load financial posting cycle, a primary database node may fail mid-transaction.
In such scenarios:
- Failover mechanisms must activate instantly
- Active transactions must not be lost or duplicated
- Users should not experience system downtime
If recovery processes are not validated, even short disruptions can lead to data inconsistencies and operational delays across business functions.
Types of Resilience, Reliability, and Availability Testing
| Test Type | Purpose | Enterprise Example |
| Failover Testing | Validate continuity when critical components fail. | Primary DB node crashes during order posting. |
| Recovery Testing | Ensure the system returns to a stable state after disruption. | Batch scheduler restarts mid-payroll cycle. |
| Chaos Testing | Introduce controlled failures to observe system response. | Killing app pods while planners run MRP workloads. |
| Fault Injection Testing | Simulate network, latency, or service degradation. | Deliberately slowing the tax engine API during invoice posting. |
| Availability Testing | Measure uptime consistency and SLA adherence. | Ensuring 99.95% uptime during peak retail season. |
| Redundancy Testing | Validate backup resources and data replicas | Switch to the standby cache cluster when the primary misbehaves |
Requirements to Understand
- A clear map of every dependency your enterprise workflows rely on, including databases, queues, cache clusters, external APIs, schedulers, and internal services.
- Documented failover paths and recovery rules that define how each component behaves when something upstream or downstream disappears.
- Access to a safe test environment where you can break things on purpose without disturbing business operations.
- Deep observability across every tier so you can track what happened before, during, and after a disruption.
- Replication and backup configurations that match production behavior closely enough to expose subtle consistency issues.
- Defined RTO/RPO expectations agreed upon by engineering, operations, and business leaders.
- Operational logs and audit trails that allow you to verify whether the system recovered cleanly or left hidden inconsistencies behind.
How to Design Reliability, Availability, and Resilience Tests
Designing these test cases involves a systematic approach:
- Identify Single Point of Failure: You start by tracing the business journeys that cannot afford downtime and then isolate the components they depend on most heavily. That exercise usually exposes fragile areas: an overloaded message broker, a lone reporting server, or a database replica that constantly lags behind its primary. These chokepoints become prime candidates for resilience testing.
- Define Failure Scenarios based on Operational Reality: The next step is choosing disruptions that mirror what actually happens in enterprise ecosystems. In this step, you make scenarios that represent the types of failures your platform has encountered before or is likely to face during peak cycles.
- Establish Recovery Targets and Success Criteria: You outline how fast the system should failover, how cleanly it must restore service, and how you expect transactions to behave while the recovery unfolds. These targets give the test a finish line and turn chaotic experiments into measurable outcomes that the business can trust.
- Validate the State of the System After Recovery: When the dust settles, you verify whether the platform preserved data integrity. You check for records that were partially processed, duplicated, abandoned, or silently lost. This step determines whether your system survived the failure or merely stayed online while accumulating inaccuracies.
Sample Test Case
| Test Case | Scenario | Expected Behavior |
| DB Failover Under Load | Terminate primary DB node during financial posting with 300 concurrent users. | Failover should complete within the target window, and the application should reconnect without user intervention or missing ledger entries. |
| Service Pod Termination | Kill multiple service pods while 5,000 users create orders. | Remaining pods should handle traffic without collapsing. Autoscaling should restore capacity smoothly. |
| Integration Latency Injection | Inject 300ms latency into the external tax engine during invoice creation. | The system should delay gracefully without invoice corruption. |
| Batch Engine Restart | Restart payroll scheduler mid-cycle. | The job should resume from the last safe point, and the final output should reconcile with the expected totals. |
3. Security and Compliance Testing
An enterprise software shouldn’t be just high-performing or full of functionalities; it should be secure and meet the necessary compliances as well. Security and compliance testing ensure that your app doesn’t just claim to be secure, but provides documented evidence that withstands auditors, regulators, and real attackers.
Security testing includes taking all the necessary measures to prevent any malicious activity from happening, whereas compliance testing proves alignment with GDPR data minimization, PCI-DSS tokenization, SOX financial controls, HIPAA health data protections, or any other industry-relevant compliance.
These tests protect the software from attackers, legal penalties, and breaches, and provide assurance to the users that their data is in good hands.
Example:
In enterprise systems handling payroll or financial transactions, a security gap can expose sensitive data such as employee salaries or vendor payment details.
If access controls fail or APIs are not properly secured:
- Unauthorized users may access restricted data
- Sensitive financial information may be exposed
- Compliance violations can lead to legal and financial consequences
Security testing ensures these risks are identified and mitigated before production.
Types of Security and Compliance Testing
| Test Type | Purpose | Enterprise Example |
| Vulnerability Scanning | Identify known security vulnerabilities automatically. | Scanning the ERP web app for outdated components or OWASP Top 10 risks. |
| Penetration Testing | Simulate real-world attacks to validate resistance. | Engaging ethical hackers to breach payroll or vendor payment modules. |
| Authentication & Authorization Testing | Confirm proper identity and permission enforcement. | Validating RBAC and MFA behavior across HR data access. |
| API & Integration Security Testing | Examine the security of internal and external APIs. | Stress-testing tax engine and bank gateway integrations for abuse patterns. |
| Data Protection & Encryption Testing | Validate data encryption in transit and at rest. | Ensuring sensitive fields like SSNs or salary figures are encrypted and cannot be read in logs. |
| Compliance Validation | Assess alignment with legal and industry standards. | Verifying audit logging, retention policies, and incident response readiness against GDPR or SOX. |
Security and Compliance Testing Requirements
- A clear inventory of all entry points, internal services, third-party APIs, and data stores that could be attacked, misused, or misconfigured.
- Defined authentication and authorization policies, including RBAC, SSO, MFA, token lifetimes, and session behavior.
- Up-to-date threat models and attack scenarios that reflect both common exploit patterns and your organization’s specific risk profile.
- Access to security scanning tools, ethical testing frameworks, and penetration testing expertise that can simulate real attacker behavior.
- Logging and monitoring mechanisms capable of capturing suspicious events, alerting on anomalous patterns, and storing audit trails per regulatory retention requirements.
- Documentation of applicable compliance standards such as PCI-DSS for payment flows, GDPR for personal data, SOX for financial controls, and ISO/IEC 27001 for information security management.
- Test environments equipped with secure configurations that mirror production, including encrypted communication, firewall rules, and segmentation where appropriate.
How to Design Security Tests?
- Understand the Threat Specific to Your Platform: The first step in designing a security test is to map threats that matter to your enterprise operations. Threat modeling helps you prioritize test cases that expose the most impactful vulnerabilities.
- Define Clear Security KPIs and Benchmarks: Before running any tests, you need to establish what success looks like in measurable terms. For instance, do access controls isolate data of different departments, or can an unauthenticated user scrape vendor pricing? Defining such benchmarks anchors your testing in verifiable outcomes.
- Execute Automated Scans and Manual Penetration Tests: Automated vulnerability scanning helps you surface outdated components and known weaknesses using tools designed to check against the OWASP Top 10 and beyond. Ethical hackers, guided by your threat models, simulate real attack paths, chain multiple weaknesses together, and validate whether your system really stops them.
- Validate Access Policies Under Load: This step involves validating how authentication and authorization behave under pressure. You examine how access controls hold up in isolation, but as part of a busy enterprise rhythm where performance and security intersect.
- Verify Compliance Requirements: Different regulations have different requirements. You need to map relevant clauses to test cases that confirm whether your system structures, logs, retention policies, and response plan truly align.
Sample Test Case
| Test Case | Scenario | Expected Behavior |
| Vulnerability Scan Against ERP Frontend | Automated tool scans for outdated libraries and OWASP Top 10 exposures. | No critical vulnerabilities with low-risk findings scheduled for patching. |
| Role-Based Access Control Validation | Finance user attempts to access HR salary data. | Access denied with logged event and audit trail captures attempted violation. |
| Penetration Test of Vendor Payment Workflow | An ethical hacker attempts to chain multiple injections and logic flaws. | All attacks are blocked without exposing any sensitive data. The incident should be reported with traceable logs. |
| Encryption Validation of Sensitive Fields | The system processes employee IDs and tax info. | Data remains encrypted in transit and at rest. Logs never contain raw sensitive values. |
| Compliance Audit Simulation | Simulated GDPR request for data export and erasure. | Data export contains only permitted fields and logs deletion events per retention policies. |
4. Usability and Accessibility Testing
Usability testing doesn’t focus on aesthetics but more on whether users can complete their daily work without feeling confused or frustrated by the enterprise software. In any case, if usability falls short, productivity will eventually collapse before performance or security issues appear.
Accessibility testing extends that mission by ensuring that your enterprise software doesn’t exclude users who rely on assistive tools or alternative input methods.
Example:
Consider a manager approving dozens of purchase orders during peak operational hours.
If the workflow:
- Requires excessive navigation
- Lacks clear error feedback
- Slows down under load
It directly impacts productivity and decision-making speed across the organization.
Types of Usability and Accessibility Testing
| Test Type | Purpose | Enterprise Example |
| Task Efficiency Testing | Measures how easily users complete frequent workflows. | Verifying how many steps are needed to create or approve a purchase order. |
| Navigation Flow Testing | Evaluates logical structure and clarity of paths. | Testing whether managers can find payroll reports without searching endlessly. |
| Accessibility Compliance Testing | Checks WCAG and assistive technology support. | Ensuring screen readers correctly interpret HR forms and tables. |
| Cognitive Load Testing | Assesses mental effort required to use the system. | Auditing complex financial posting screens for overwhelming design. |
| Error Handling and Feedback Testing | Examines clarity of messages and recovery options. | Confirming the invoice-upload errors guides users to fix incorrect fields. |
| Keyboard and Shortcut Testing | Validates efficiency for expert users. | Ensuring planners can navigate MRP screens without relying on a mouse. |
Requirements for Usability and Accessibility Testing
The following are the things you need to keep in mind while performing this non-functional testing type on your enterprise software:
- Access to real user personas that represent supervisors, auditors, analysts, and clerks.
- Representative test data that mirrors everyday enterprise scenarios.
- A UI instrumentation setup that captures click paths, hesitations, failed attempts, and navigation depth.
- Assistive tools include screen readers, keyboard-only mode, magnification software, and accessibility validators.
- Clear definitions of the happy path and high-frequency path workflows that drive most business operations.
- Enterprise-specific usability benchmarks tied to productivity.
- Logging that records users' errors and UI validation behavior to evaluate frustration points and design gaps.
How to Write Usability Test Cases
- Identify High-Frequency Test Cases: The first step here is to map out the tasks users repeat dozens or hundreds of times per day, as these are the workflows where poor usability drains productivity.
- Build Realistic User Journeys: A single screen rarely tells the full story. Enterprise users weave through chains of modules. With that in mind, you need to design tests that reflect these cross-module journeys rather than examining pages in isolation.
- Define KPIs: Before involving users, you need to establish what you consider successful behavior. Number of clicks, time per task, error frequency, screen-reader accuracy, and visual contrast thresholds are the metrics that anchor the test to measurable outcomes.
- Observe Real Interactions: Now, watch how users move, hesitate, backtrack, or search. These patterns will reveal pain points that no functional test case would notice.
- Use Findings for Better Design: Once the patterns emerge, it's time to convert them into specific recommendations that simplify workflows. Remember that small improvements compound into dramatic productivity gains across large teams.
Sample Test Case
| Test Case | Scenario | Expected Behavior |
| Purchase Order Approval Flow Audit | The manager approves 50 purchase orders during peak hours. | Approval requires minimal navigation. |
| Keyboard-Only Navigation Test | Planner navigates the MRP workbench using only keyboard shortcuts. | Focus order is logical, where shortcuts work consistently, and no UI element becomes inaccessible without a mouse. |
| Screen Reader Evaluation for HR Forms | HR staff completes employee profile updates using a screen reader. | Labels are correctly announced where grouping and hierarchy make sense. |
| Error Feedback Review on Invoice Upload | The user uploads a bulk invoice file with multiple incorrect fields. | Error messages point directly to problematic rows, corrective guidance is specific, and the user can reattempt the upload without restarting the workflow. |
5. Compatibility Testing
Organizations use a plethora of devices, including varying screen sizes, operating systems, hardware options, and device types. Your enterprise software should behave consistently everywhere it’s expected to run.
Undeniably, it’s one thing to build a platform for a controlled environment, but it's another to deploy it across a company where every team has unique hardware, browser versions, operating systems, and network setups.
Furthermore, the challenge is bigger in global enterprises where you don’t have control over the ecosystem. The best thing you can do is to adapt accordingly.
With compatibility non-functional testing, you can test whether your software works consistently across various requirements. Your enterprise software should be tested across various permutations and combinations of devices, operating systems, screen sizes, and more to ensure it functions seamlessly on all devices.
Example:
In large organizations, users access enterprise systems across different environments:
- Desktop browsers (Chrome, Edge, Firefox)
- Mobile devices and tablets
- Corporate VPN networks with varying latency
If compatibility issues occur, critical workflows such as payroll processing or order management may fail for specific user segments without visibility to engineering teams.
Types of Compatibility Testing
| Test Type | Purpose | Enterprise Example |
| Browser Compatibility Testing | Ensures UI behaves consistently across browsers. | Testing Chrome, Edge, Firefox, and Safari during payroll approval workflows. |
| OS Compatibility Testing | Validates system behavior on different operating systems. | Running ERP dashboards on Windows, macOS, and Linux environments. |
| Device Compatibility Testing | Checks usability and performance across device types. | Verifying HR self-service on mobile, tablet, and desktop. |
| Network Compatibility Testing | Examines behavior under varied network conditions. | Testing ERP access over VPN, low bandwidth, or high-latency corporate networks. |
| Regional & Localization Compatibility | Confirms system adapts to time zones, currency, and formats. | Ensuring date formats and number formatting behave correctly across regions. |
| Configuration Compatibility Testing | Checks diverse enterprise setups and security policies. | Verifying software response under different group policies, VPN rules, and SSO configurations. |
| Backward Compatibility Testing | Check version changes. | Verifying that any new version update functions correctly on legacy devices. |
Requirements for Compatibility Testing
- A documented list of supported browsers, versions, devices, OS distributions, and network conditions used across the enterprise.
- Access to environments that mimic corporate setups, including VPNs, proxy servers, firewalls, and endpoint security configurations.
- A comprehensive mapping of regional behaviors, including locale, currency, number formats, and date/time conventions.
- Testing tools or virtual labs capable of replicating multiple configurations without overspending on physical devices.
- Clear baseline expectations for UI behavior, layout consistency, and workflow accessibility across platforms.
- Logs and telemetry that capture browser or device-specific failures that are invisible to the backend.
- Cross-team coordination with IT, security, and infrastructure teams to ensure accurate representation of endpoint constraints.
How to Design Compatibility Tests
- Identify the Environment Diversity: Start by discovering the landscape your users operate in. Large enterprises rarely follow a single standard. Your goal is first to identify the diversities within the user base.
- Select Representative Combinations: Compatibility testing is all about testing various combinations. However, trying every possible configuration is a trap. You need to pair certain browsers with high-frequency workflows, certain OS versions with memory-intensive modules, and specific networks with workflows that involve large data transfers.
- Define Expected Behavior: Prior to writing any test case, make sure to decide what correct looks like for every configuration. Setting a baseline helps verify whether the software holds up across environments or silently deviates.
- Design Workflow-Centric Compatibility Test Cases: When designing test cases, you need to frame them around tasks. Capture how the software behaves end-to-end across browsers, devices, and network conditions.
- Record Deviations: Make sure to record every inconsistency with sufficient detail, allowing developers to replicate the issues. Your test case should close with documented evidence, making the incompatibility impossible to ignore.
Sample Compatibility Test Case
| Test Case | Scenario | Expected Behavior |
| Cross-Browser Payroll Entry Test | Perform payroll adjustments on Chrome, Edge, Firefox, and Safari. | The layout remains intact, and no browser-specific script errors. |
| Mobile vs. Desktop HR Self-Service Flow | Submit leave requests via mobile app and desktop browser. | Forms render correctly, file attachments work on both devices, and the session remains stable. |
| VPN Network Compatibility Check | Access ERP over corporate VPN with variable latency. | Pages load without timeout. |
| Regional Formatting Verification | Test order creation in EU and US locale settings. | Currency, decimal formats, and date fields follow region-specific rules without breaking validation. |
6. Observability Testing
Observability testing evaluates whether your metrics, logs, traces, dashboards, alerts, and operational workflows showcase the true picture. Without it, outages become mystery hunts costing thousands per hour while engineers stare at dashboards showing everything green.

Teams with mature observability cut mean time to resolution by 50-70%, turning panic into precision.
Example
During a payroll cycle, if a database replica fails and an external banking API introduces latency, the system must provide clear visibility into:
- Where the delay originated
- Which services were impacted
- How the failure propagated across the workflow
Without proper observability, teams spend hours diagnosing issues that should be resolved in minutes.
Types of Observability Testing
| Test Type | Purpose | Enterprise Example |
| Metrics Verification Testing | Validates the collection of system and business KPIs. | Confirming that ERP posting latency, queue depth, and throughput are accurately recorded. |
| Log Completeness and Structure Testing | Ensures logs contain actionable and contextual data. | Checking HR audit logs for user ID, action, timestamp, and outcome. |
| Distributed Tracing Validation | Confirms end-to-end visibility in multi-service workflows. | Tracing an order from UI to inventory, pricing, tax, shipping, and finance. |
| Alert Accuracy and Threshold Testing | Ensures alerts fire at the right time with meaningful detail. | Triggering DB saturation to verify that alerts reach SREs before users feel the impact. |
| Dashboard Integrity Testing | Checks the correctness and timeliness of observability dashboards. | Validating that financial close dashboards correctly display backlog and bottlenecks. |
| Incident Simulation Testing | Evaluates operational readiness and signal usefulness. | Simulating a failed external tax engine during invoicing. |
Requirements for Observability Testing
- Defined KPIs that matter both technically and operationally.
- Logs that follow structured formats with trace IDs, contextual fields, and meaningful severity.
- A consistent tracing strategy across all services, including cross-service propagation of correlation IDs.
- Dashboards that show system health and business transaction flow without requiring manual decoding.
- Alert rules informed by real-world patterns instead of arbitrary defaults.
- Access to tools that support distributed tracing, metrics, log aggregation, analytics, and anomaly detection.
- A test environment that allows safe failure simulation without muting telemetry.
How to Design Observability Tests
- Map Business Workflows: The initial step in this process is to figure out which signals matter when the system begins misbehaving. You need to identify the exact telemetry required to observe that journey. If part of the workflow vanishes from view, you already know where observability needs strengthening.
- Identify the Signals Workflow Must Produce: After choosing the workflow, you need to map the telemetry that it should naturally emit. You will define which signals must appear when the workflow is healthy, when it slows down, and when it begins to falter.
- Specify the Conditions: To ensure the context is clear, describe how the workflow will be executed. Whatever the scenario, you should document the conditions so the test case reflects a realistic enterprise state.
- Define Visibility Expectations: By this step, your test case will state what observability should reveal. Now, you need to articulate concrete expectations that will turn subjective into verifiable.
- Establish Pass/Fail Criteria: The final part in this process is to establish pass/fail criteria. You need to determine what success looks like clearly, ensuring that two different evaluators would reach the same judgment.
Sample Test Case
| Element | Specification |
| Test ID | OBS-PAYROLL-001 |
| Scenario | Database replica failure during peak payroll + external bank API delay. |
| Injected Failure | Kill the read replica, and inject 5s latency to the bank validation service. |
| Expected Telemetry | Payroll job lag metric > threshold, trace showing bank API timeout cascade, error rate spike. |
| Success Metrics | Alert fires in <90s, and SRE identifies root cause in <8 minutes using dashboards |
| Environment | Staging payroll system with a full observability stack (metrics/logs/traces). |
| Pass Criteria | Complete incident resolution path documented, and runbook created. |
| Validation | Replay telemetry in ops training, confirm < 5-minute resolution. |
Enterprise Non-Functional Testing Readiness Checklist
- Do you have defined NFRs with measurable KPIs?
- Can your system handle peak load scenarios without degradation?
- Are failover and recovery scenarios tested regularly?
- Do you have full observability across critical workflows?
- Are compliance and security validations part of your testing cycle?
If any of these answers are unclear, your system is operating with hidden risk.
Conclusion
Move from Assumptions to Measurable Assurance
Most teams discover non-functional gaps only after production incidents.
By then, the cost is already paid in downtime, lost revenue, and customer trust.
ThinkSys helps enterprise teams:
- Define measurable non-functional requirements
- Build production-grade testing strategies
- Execute high-impact performance, resilience, and security testing
- Establish long-term quality engineering practices
If you’re scaling your platform or preparing for high-risk releases, now is the time to validate your system under real-world pressure.
At enterprise scale, even small performance or reliability gaps compound into significant business risk.