How to Reduce Flaky Tests in Automation Frameworks
Summarize With:

Gaurav Joshi
A flaky test passes and fails on the same code without any change, and it's an architecture problem, not a test problem. The fixes that work: track cumulative unique flaky tests (not per-run rate), treat quarantine as a coverage debt with owners and deadlines, debug failure clusters instead of individual tests, build isolation into the framework (condition-based waits, data factories, cached auth), and make ownership automatic. Retries are not a fix, they're a $100K/year way of hiding the problem.
What Is a Flaky Test?
A flaky test is a test that produces different results; pass or fail on the same code, with no changes in between. Run it ten times, get eight greens and two reds, change nothing. That's flake.
The danger isn't the failed runs. It's what flaky tests do to your team: once developers learn that red might mean nothing, they stop trusting red. Reruns become reflex. The CI gate still exists, but it stops gating anything.
What Causes Flaky Tests?
Almost every flaky test traces back to one of eight causes:
- Timing and async waits: The test checks for an element before the app finishes rendering. Hard-coded sleeps "fix" it until the environment slows down by 200ms.
- Test-order dependency: Test B passes only when test A ran first and left the right state behind. Run them in parallel or shuffle the order, and B breaks.
- Shared state: Two tests touch the same user account, database row, or cache. Alone, each passes. Together, they collide.
- Test data collisions: Shared fixtures mutated by one test and assumed pristine by the next.
- Concurrency: Race conditions in the app (or the test) that only appear under parallel execution.
- Time and date logic: tests that pass every day except the last day of the month, or in every timezone except the CI runner's.
- Environment instability: Under-resourced CI runners, cold containers, network blips.
- Third-party dependencies: Real external APIs in the test path, failing on their schedule instead of yours.
Notice what's not on the list: "the testing framework." Playwright, Cypress, and Selenium get blamed constantly, but the framework is almost never the root cause. The architecture around it is.
Pipeline Red Right Now? Start Here
If you're firefighting today, do these four things in order, the strategy can wait 48 hours:
- Pull the last 60 days of CI data and count distinct tests that flaked, not failure instances. Ten failures from one test is a repair job; ten failures from ten tests is an architecture problem.
- Cluster failures by timestamp. Tests that fail together share a cause, an environment, a data collision, a deploy window. Fix the cause, clear the cluster.
- Grep for hard waits:
grep -r "waitForTimeout" tests/ | wc -l (or sleep/cy.waitwith fixed values). Every one is a deferred flake. This number is the fastest health check we run on any suite we inherit. - Quarantine the worst offenders: With a name and a fix-by date on each. Quarantine without ownership isn't triage; it's coverage quietly leaving your suite.
Then come back and do the five fixes properly.
Three Questions to Find Out If You Actually Have a Problem
Before any solution, you need an honest read on your current exposure. Most teams are watching the wrong metric and drawing the wrong conclusion from it.
Answer these three questions using your actual CI data from the last 60 days.
- Question 1: How many distinct tests have failed flakily at least once in the last 60 days? Not how many times tests failed (how many unique tests).
- Question 2: Of the tests currently in your quarantine folder, how many have a named owner and a documented fix-by date?
- Question 3: Does anyone correlate failure timestamps across tests, or is every failure investigated alone?
You’ll See Results Like These
| Signal | Healthy | Warning | Critical |
| Unique flaky tests in 60 days | < 2% of the suite | 2–5% of the suite | > 5% of the suite |
| Quarantined tests with the named owner | All of them | Some of them | None or few |
| Failure timestamp correlation done | Yes, regularly | Once or never | Never attempted |
| Per-execution flaky rate | < 1% | 1–3% | > 3% |
| Team reaction when CI fails | Investigates root cause | Re-runs and moves on | Doesn't notice anymore |
If you're in the right-hand column for two or more rows, the retry budget you're spending isn't buying stability. It's buying silence.
Read Also: Top QA mistakes to avoid
Fix 1: Stop Tracking the Wrong Number
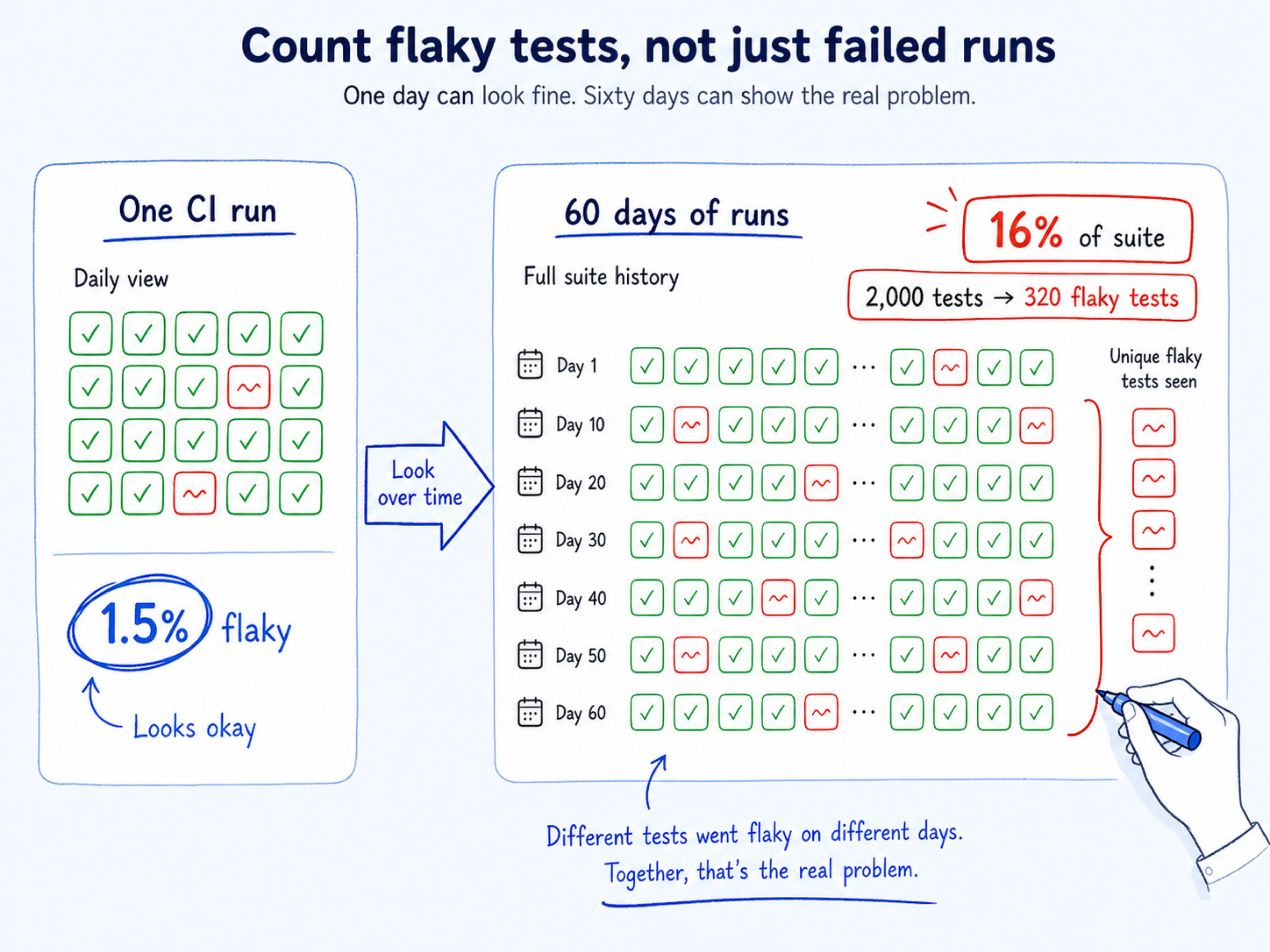
Most teams track per-execution flaky rate — flaky results divided by total runs. It looks small and stays small while the problem grows.
Here's why: John Micco's research at Google showed that a 1.5% per-execution flaky rate touches 16% of your total test inventory over time. The per-run number whispers while a sixth of your suite becomes untrustworthy.
What to do instead:
The metric you are watching tells you how many runs failed today. What you actually need to know is how much of your suite can no longer be trusted.
How We Approach This at ThinkSys
- Switch your primary monitoring metric: Pull your CI logs for the last 60-90 days and count unique tests that have failed flakily at least once; that is your real exposure number, not the per-run rate.
- Set a cumulative threshold: Alert when unique flaky tests exceed 5% of the suite
- Build a trend dashboard: Is the count of newly flaky tests rising or falling month over month?
- Report both numbers in sprint reviews: List down per-execution rate alongside cumulative inventory impact. The gap between them is what tells you whether your situation is stable or quietly getting worse.
(For the full measurement stack: flake rate, retry rate, first-attempt pass rate, quarantine dwell time, see our Playwright testing KPIs guide.)
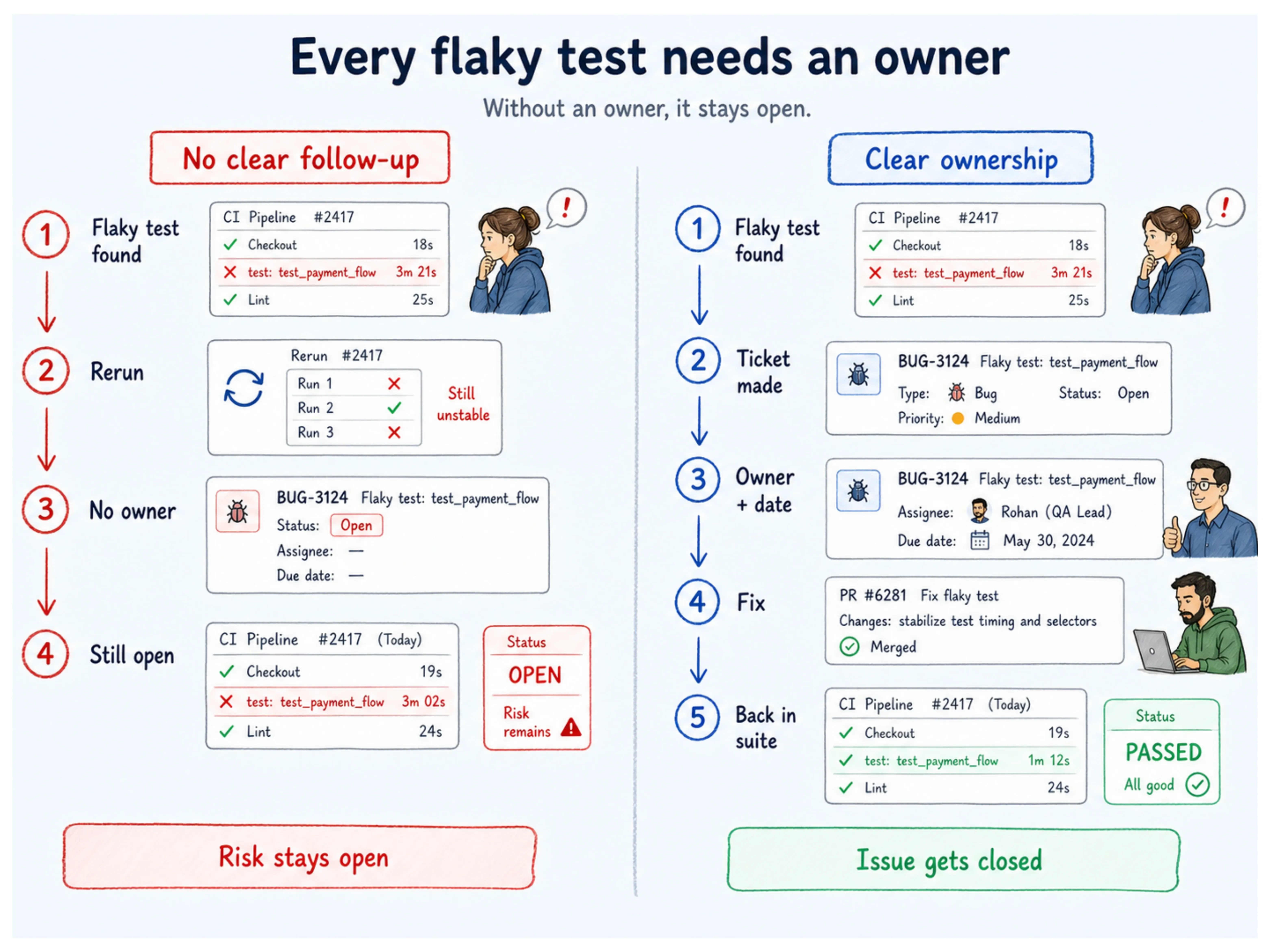
Fix 2: Treat Quarantine as a Coverage Ledger
Open your quarantine folder right now. Find the oldest test in it. Check when it was quarantined, then check whether a single comment, commit, or ticket explains why it was moved there or when it is coming back.
For most teams, the honest answer is: it was flagged, it was moved, and that was the last anyone thought about it. The test is still counted in your inventory. The coverage it was supposed to provide is quietly gone.

Martin Fowler named this failure mode directly, quarantined tests stop helping with regression coverage, and without accountability, the quarantine folder becomes a one-way door. Atlassian built its Flakinator system precisely because it knew engineers would not follow up on quarantined tests voluntarily.
Their fix was automatic routing to a named owner, a ticket, and a deadline. The design assumption was explicit: good intentions are not enough.
Every test behind that door is a regression your suite will no longer catch. Your coverage percentage looks the same. Your actual coverage does not.
What ThinkSys Does Differently Here
- Audit your quarantine list this sprint: We assign a named owner and a fix-by date to every test in it. Any test that cannot get an owner this sprint gets removed from inventory, and the coverage gap gets documented explicitly, not silently absorbed.
- Put a quarantine SLA in place: No test stays quarantined longer than two sprints without a documented root cause and an active ticket attached to it.
- Make the count visible in your pipeline: Quarantined test totals should appear in every CI summary. Rising counts trigger a team-level review, not just a quiet individual follow-up.
- Build a re-entry gate: A test coming out of quarantine needs a documented fix and at least 10 consecutive clean runs before it is restored to the active suite.
Note: If your quarantine list only grows, you're not managing flake. You're archiving it.
Fix 3: Debug Root Causes, Not Individual Tests
The single biggest waste in flaky-test work is debugging tests one at a time when they fail together.
Understand it with an example: an engineer spends three hours chasing a flaky timeout in the payment confirmation test and fixes a hardcoded wait. The next week, a different engineer spends two hours on a race condition in the checkout flow. Different tests, different people, different days, but both failures trace to the same shared resource: a test environment database that is not properly isolated between parallel runs.
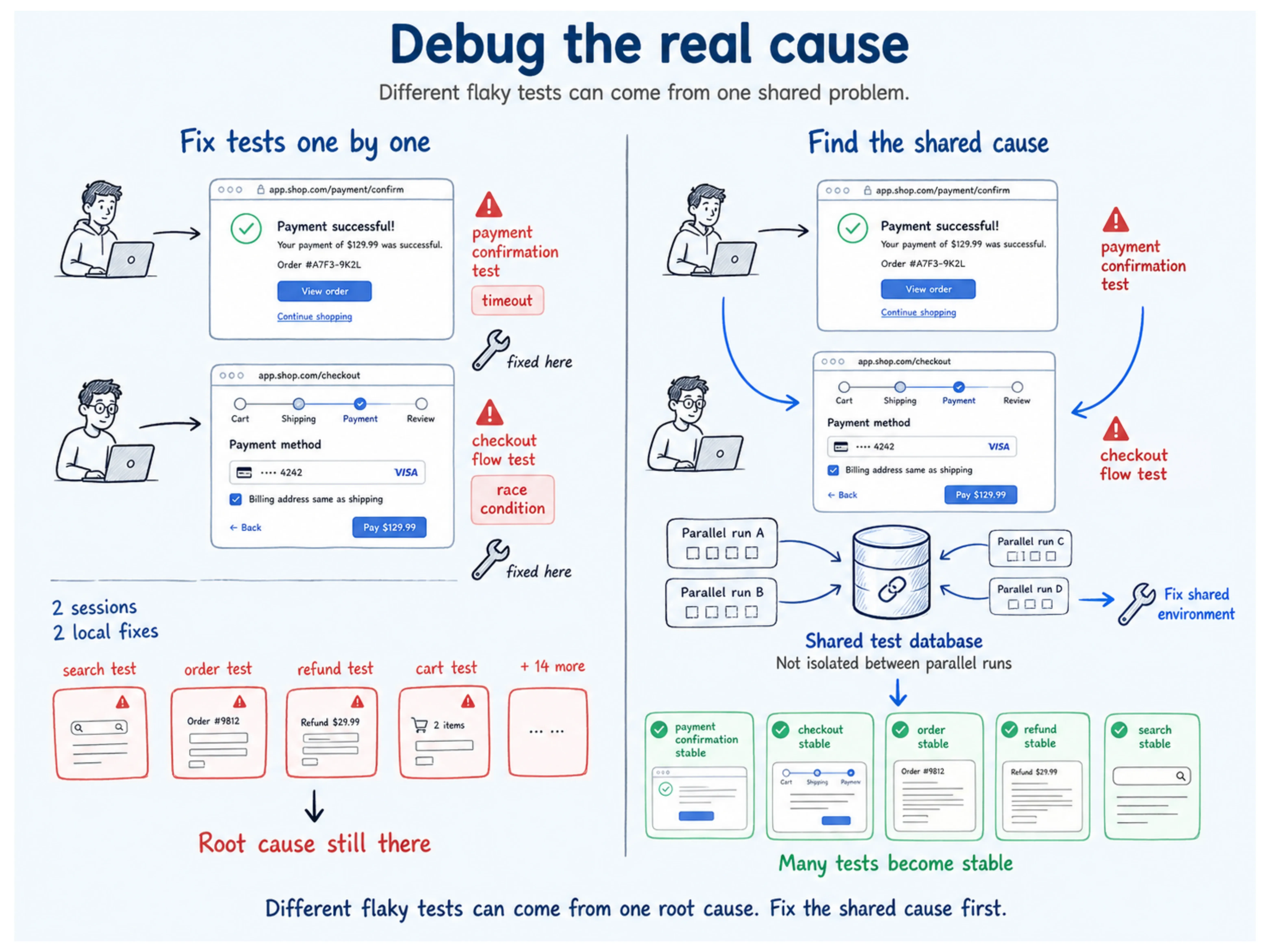
Two engineering sessions. One root cause. Fourteen more tests in quarantine with the same underlying condition, still waiting.
A 2025 University of Sheffield / Carnegie Mellon study found that 75% of flaky tests fail in correlated clusters, with a mean cluster size of 13.5 tests. That's not thirteen problems. That's one problem with thirteen symptoms, a shared environment issue, a data collision window, a service dependency.
The cost asymmetry is brutal. Daimler Truck AG's analysis put manual investigation at $5.67 per flaky failure versus $0.02 for a retry, which is exactly why teams default to retries, and exactly how the root cause survives to flake another day.
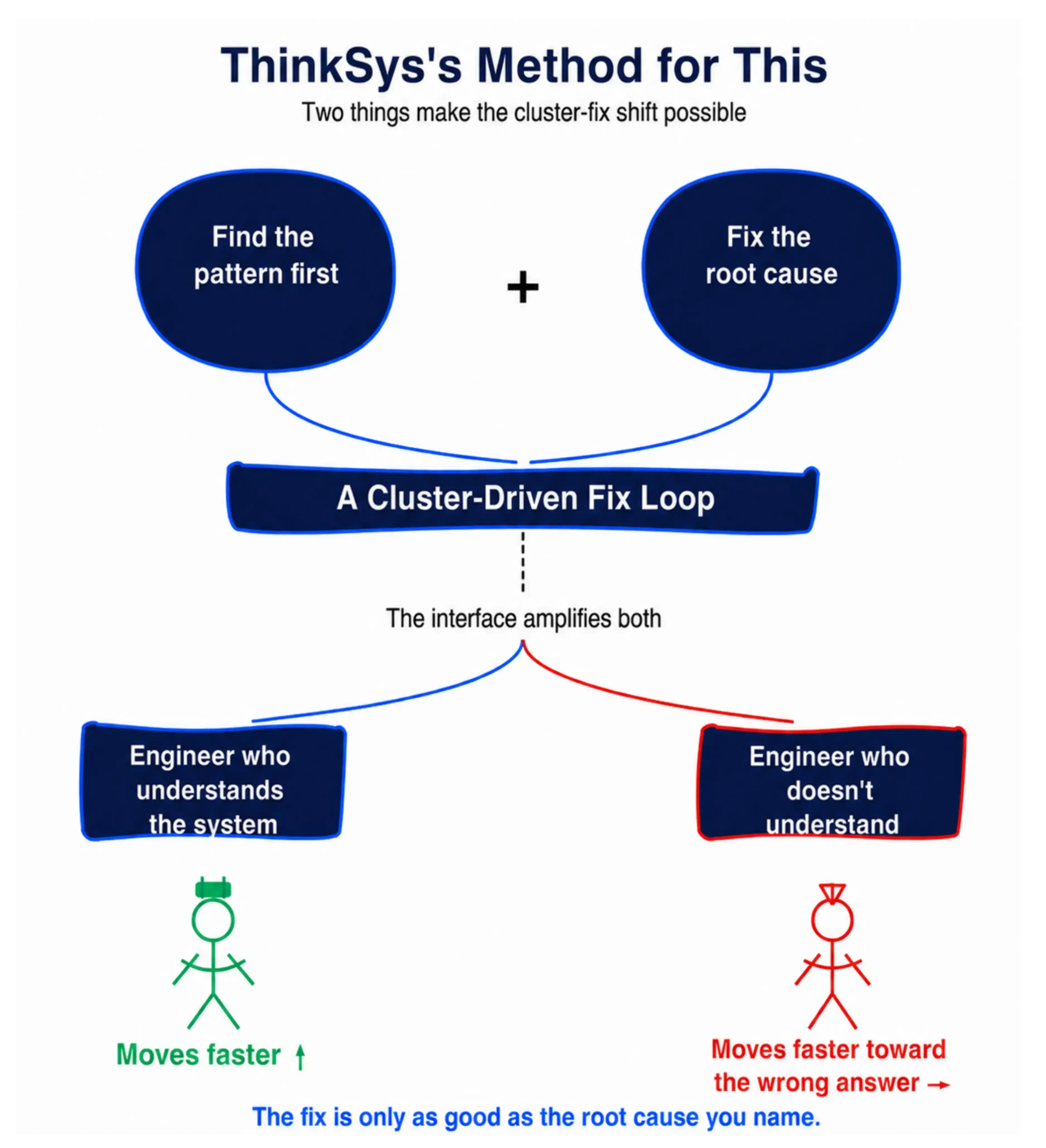
The clustering workflow:
- Before your team touches a single test, run timestamp correlation: Pick your last 30 flaky failures. Group the tests that fail within the same CI window; those groups are your clusters, and each one likely shares a single root cause.
- Name the condition: The same three to five conditions appear repeatedly across most suites: non-isolated environment state, shared test data, timing dependencies in async operations. Categorize them all by cause.
- Fix the condition: A shared database configuration causing 14 failures is one infrastructure fix, not 14 individual test repairs.
- Log what you fix and why: When a root cause is resolved, document which tests it affected and what changed. That pattern library becomes your fastest diagnostic tool the next time a cluster appears.
Fix 4: Build Isolation Into the Architecture
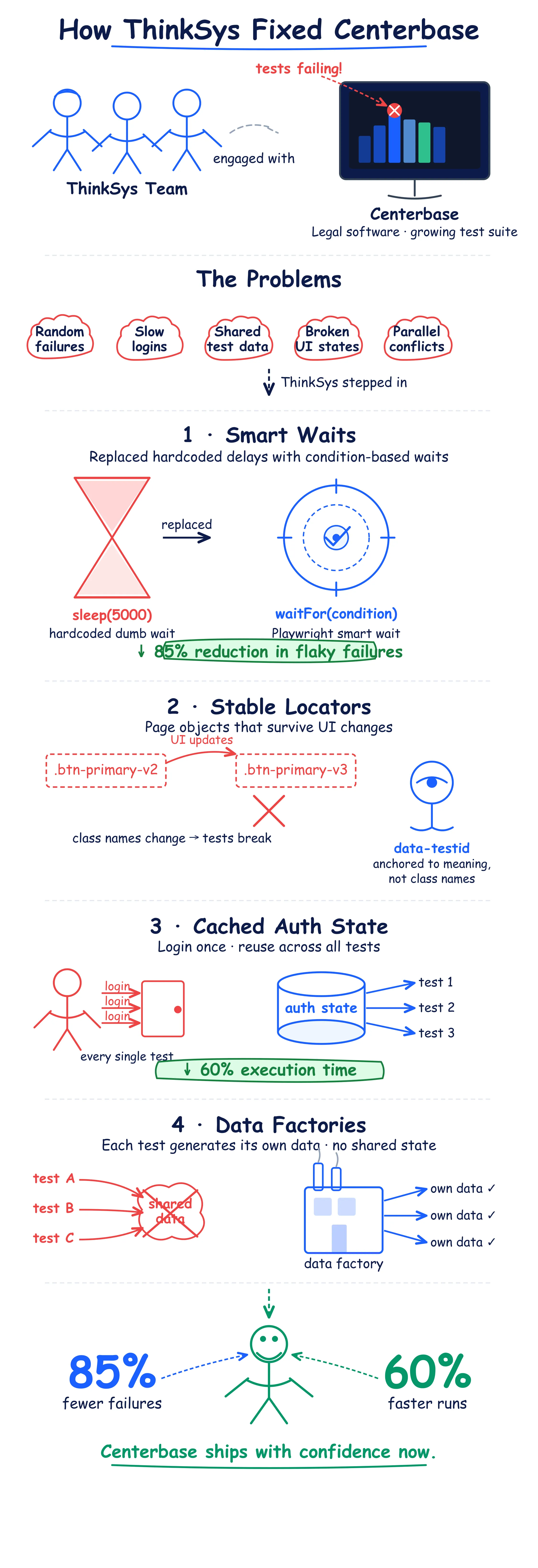
This is where flake actually gets fixed in the framework, not the test files. When we rebuilt Centerbase's suite, these changes cut flaky failures by 85% and execution time by 60%:
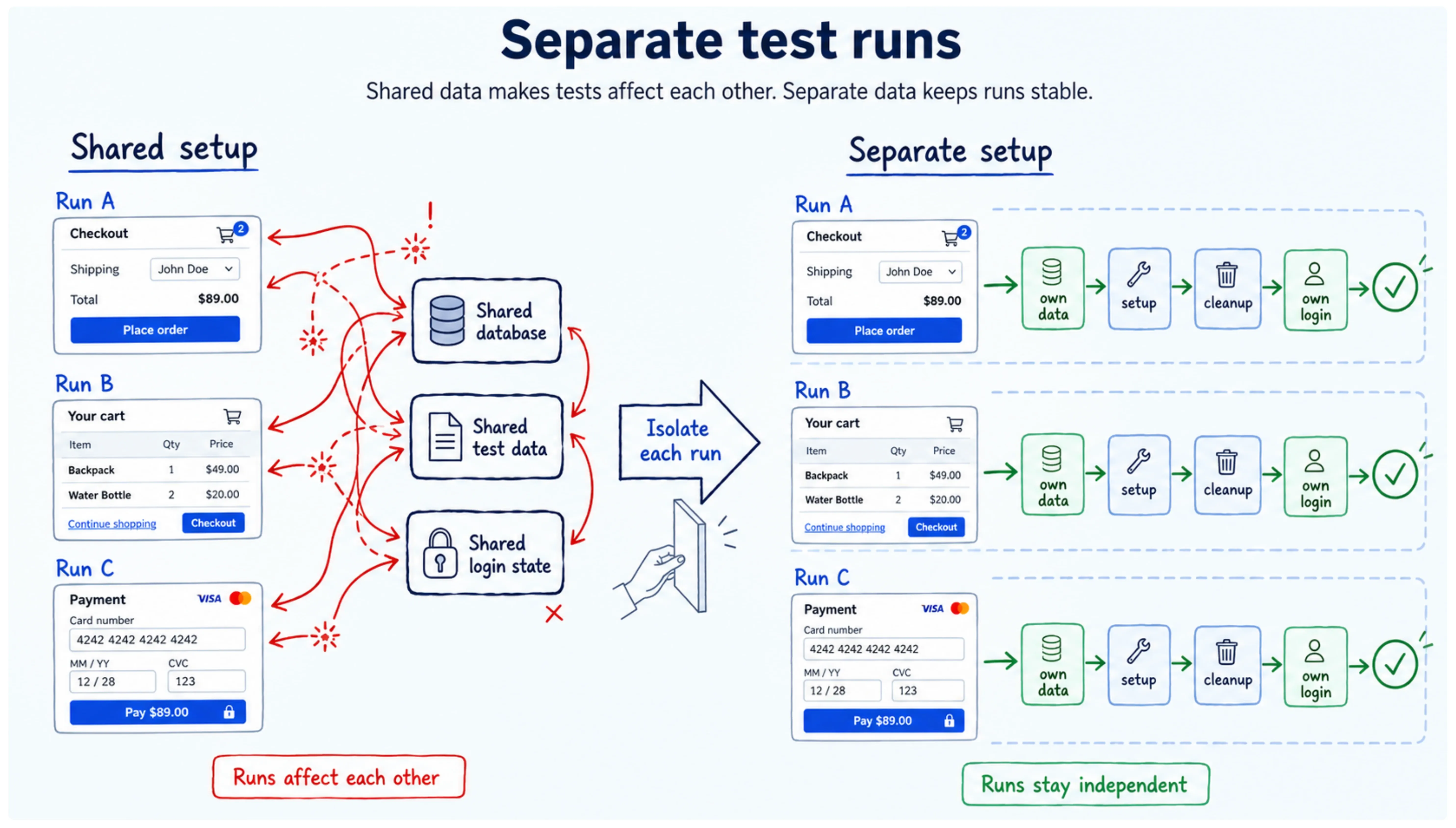
Replace hard waits with condition-based waits. The single highest-value change in most suites.
// Flaky: guesses how long rendering takesawait page.waitForTimeout(5000);await page.click('#submit');// Stable: waits for the actual conditionawait page.getByRole('button', { name: 'Submit' }).click();// Playwright auto-waits for visibility and actionabilityUse data factories, not shared fixtures. Every test creates its own isolated data and cleans up after itself:
// Flaky: every test fights over the same userconst user = SHARED_TEST_USER;// Stable: each test gets its ownconst user = await createTestUser({ role: 'admin' });- Cache authentication instead of re-logging in. Log in once, save the session state, reuse it in Playwright,
storageStatedoes this natively. At Centerbase this alone cut ~60% of execution time, and shorter runs mean fewer timing windows for flake to happen in. - Robust locators via page objects. Role- and text-based selectors (
getByRole,getByLabel) survive redesigns; brittle CSS chains don't. - Conditional logic for optional UI states: Cookie banners, onboarding modals, feature flags. Tests should handle the app as it actually behaves, not as the happy path imagines it.
- Environment isolation for parallel runners per-worker databases or namespaced data, so parallelism stops manufacturing collisions.
Framework notes
- Playwright: Auto-waiting and storageState solve most timing and auth flake natively, if your Playwright suite is flaky, look at test data and shared state first. Use
retries: 2for detection (the JSON reporter marks recovered tests flaky), never as the fix. - Cypress: Built-in retry-ability on commands helps, but
cy.wait(3000)with fixed times is the same hard-wait trap. Use route interception (cy.intercept) to wait on actual network events. - Selenium: No auto-waiting; explicit
WebDriverWaitwith expected conditions everywhere, and treat anyThread.sleepas a defect. Most "Selenium is flaky" complaints are missing-wait-discipline complaints.
Fix 5: Create Ownership Infrastructure, Not Just Ownership Intent
Spotify cut its flakiness from 6% to 4% in two months by making flaky tests visible to the people who owned them. Before a single test was repaired, the accountability structure changed, and the rate dropped.
Jason Palmer says that without confidence in your test suite, you are in no better position than a team with zero tests. What your team needs is not more intent around ownership; it is infrastructure that makes ownership unavoidable.
Naming someone in a comment and moving on does not work. Forcing functions do: automatic tickets, fix-by dates with pipeline consequences, and escalation when deadlines pass without action.
The Ownership Model ThinkSys Puts in Place

- Every flaky test gets a named owner within 24 hours of identification: Not a team. A person. The distinction matters more than it sounds.
- Automatic ticketing on detection: When a test is flagged flaky, a ticket gets created automatically in your project management tool, pre-populated with the test name, failure timestamps, and a default fix-by date. Your team should not have to remember to create it.
- Pipeline consequences: A test flagged flaky with no active owner or ticket after one sprint gets removed from the suite automatically. The coverage gap is logged. The removal forces a real decision that social accountability quietly lets teams avoid.
- Flakiness metrics in engineering reviews: Unique flaky test count, quarantine count, and mean time to resolution belong in your sprint reviews alongside velocity and bug count. What gets measured in those rooms gets managed.
Note: Infrastructure beats intent because intent doesn't survive sprint pressure. Tickets, SLAs, and pipeline rules do.
The Real Cost of Waiting
For a 100-person engineering team, the annual math looks like this:
| Cost Category | Annual Impact (100-person team) |
| Developer time investigating failures | ~$165,000 |
| Developer time repairing flaky tests | ~$195,000 |
| Retry-only "resolution" (50 failures/day) | ~$100,000+ |
| Total direct productivity loss | ~$375,000 |
Assumes ~100 engineers at blended US rates, investigation/repair time consistent with Daimler Truck AG's published per-failure costs.
And the problem is growing: Bitrise's industry reporting shows the share of teams naming flakiness a top CI problem rose from 10% to 26% between 2022 and 2025. AI-accelerated development is pushing more code, and more tests through the same pipelines.
How ThinkSys Fixes This (and When to Call)
Everything above is what we do in flaky-suite engagements, in roughly this order: run the 60-day diagnostic, cluster the failures, fix the architecture (waits, data factories, cached auth, locators), and leave behind the ownership infrastructure so it doesn't regress. It's the exact playbook from the Centerbase engagement 85% fewer flaky failures, 60% faster execution, regression cycle halved.
When to bring in outside help: when your team has been "fixing flaky tests" for two quarters and the cumulative count hasn't moved, that's the signal the problem is architectural, and inside-the-sprint effort can't reach it.
Get a free flaky-suite audit, we'll run the 60-day diagnostic and the hard-wait count on your suite and show you the clusters.