Playwright Features 2026: New AI Updates and MCP Capabilities
End-to-end testing is no longer optional. Modern web apps run across browsers, devices, and operating systems, and flaky tests slow teams down. That’s where Playwright comes in.
Playwright has quickly become the preferred choice for QA engineers and developers. It offers fast, reliable, and cross-browser testing. Unlike older frameworks, it was built for today’s single-page apps and complex user flows.
By the end of this guide, you’ll know about Playwright features and why they matter for today’s complex testing requirements.
What is Playwright?
Playwright is an open-source test automation framework created by Microsoft. It was first released in 2020 and has quickly gained adoption among QA teams and developers.
It helps automate browsers for end-to-end testing. It works with Chromium, Firefox, and WebKit, which means you can test across Chrome, Edge, Safari, and Firefox with a single API. Unlike older tools, you don’t need separate drivers or a complex setup.
Another reason Playwright stands out is its multi-language support. You can write tests in JavaScript, TypeScript, Python, Java, and .NET, making it flexible for teams with different tech stack.
Playwright is also designed to support modern web apps like SPAs (single-page applications) and PWAs (progressive web apps).
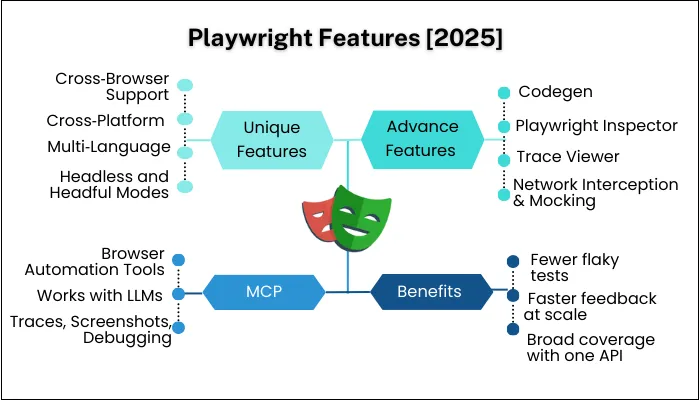
Core Playwright Features
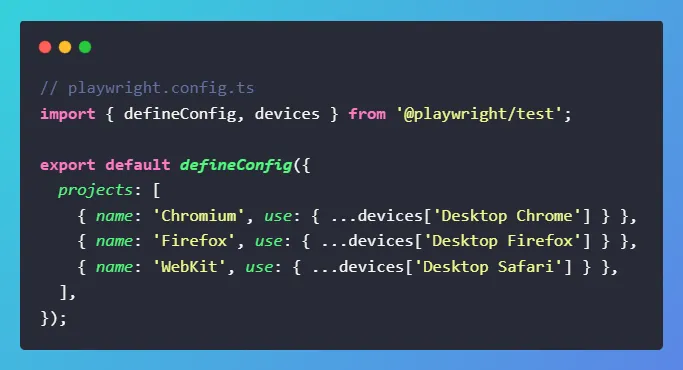
1. Cross‑Browser Support
Playwright lets you use one API to test Chrome/Edge (Chromium), Firefox, and Safari (WebKit). That matters because many bugs only show up in one engine. Instead of maintaining separate configs and drivers, you run the same tests everywhere with a small config change. This reduces code drift and cuts maintenance. It also makes your suite a real “cross‑browser” suite, not just “Chrome-only.”
You can pin versions, run all three in CI, and catch rendering, CSS, and timing differences early. Teams use this to gate releases. For example, if it passes on all engines, it ships. That’s a simple rule that keeps quality high and bug escapes low.
2. Cross‑Platform Compatibility
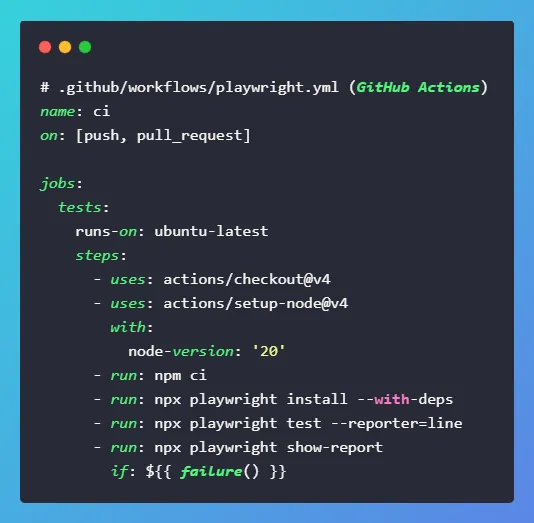
You can run Playwright on Windows, macOS, and Linux, both locally and in CI. That means your laptop, your workstation, and your build server all behave the same way.
The installer fetches the right browser binaries, so setup is fast. In CI, Playwright integrates with GitHub Actions, Jenkins, GitLab, and Azure.
You can shard tests, run in parallel, and upload HTML/trace reports as build artifacts. As a result, you see consistent, reproducible runs.
When a test fails in CI, you can reproduce it locally with the same browser + OS target. That shortens time‑to‑fix and prevents “works on my machine” issues.
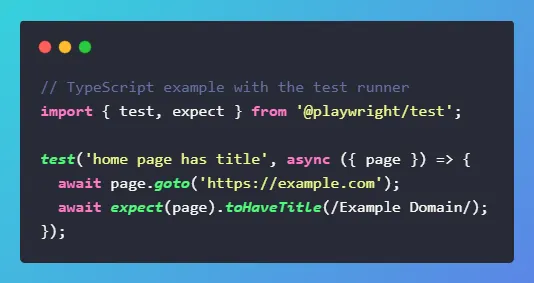
3. Multi‑Language Support
Playwright supports JavaScript/TypeScript “natively,” and also offers official bindings for Python, Java, and .NET. That lets mixed teams adopt one tool without forcing a language switch. You can standardize on a single framework while keeping devs in their comfort zone.
Docs and APIs are consistent across languages, which simplifies onboarding and reduces context switching. It also helps when you share examples across teams: the same flows map cleanly between languages.
In practice, many companies use TS for UI tests and Python/Java for service tests. Playwright works well in these hybrid setups.
TypeScript:
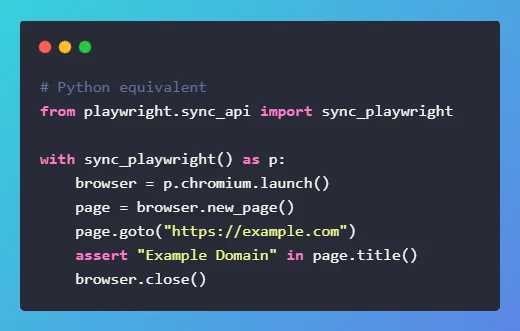
Python:
4. Headless and Headful Modes
Headless mode runs the browser without a visible window. It’s fast and perfect for CI. Headful mode shows the real browser, great for debugging and demos. You can flip between them with a flag or config.
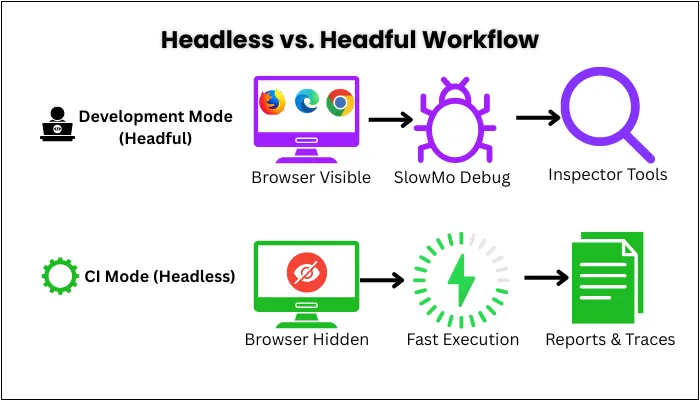
Caption:- During development, engineers use headful mode with slow motion and the inspector for clarity and debugging. In CI pipelines, tests switch to headless mode, running at full speed and capturing reports, traces, and logs.
A common workflow is that you develop in headful (with slowMo and inspector) to see what the test does, then run headless in CI for speed.
This keeps tests readable while staying fast at scale. It also helps when you need to record a short clip of a flaky step, run headful with video on, capture the behavior, fix the bug, and revert to headless for the pipeline.


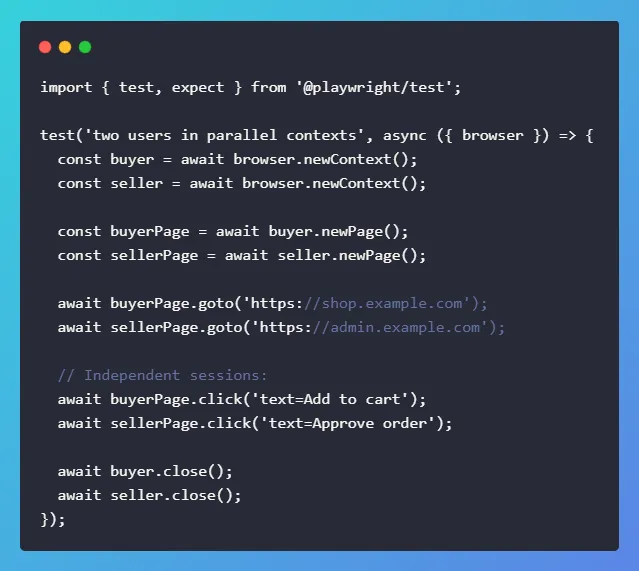
5. Isolated Browser Contexts
A “browser context” is like a clean, separate profile. Playwright lets you start many contexts inside one browser process. That gives you test isolation without the overhead of full launches. Each context has its own cookies, storage, and cache, so tests don’t leak state.
This is key for reliability (no surprise cross‑test pollution) and for multi‑user scenarios (e.g., Buyer vs. Seller in the same test). It also speeds up suites because creating a context is much faster than launching a brand‑new browser. This results in stable tests, faster pipelines, and fewer flakes.
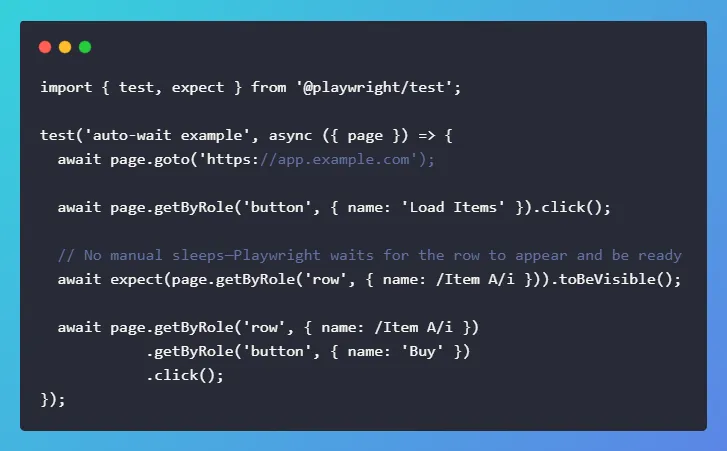
6. Automatic Waiting
Playwright waits for elements to be actionable before it clicks, types, or reads. It also waits for navigation and network to reach stable states. That means fewer manual sleep() calls and fewer timing bugs. When the DOM updates, the locator re‑resolves; when the element becomes visible, the action proceeds.
This is the biggest reason Playwright tests are less flaky than many Selenium‑style suites. You still can (and should) add explicit waits when the app truly needs them, but the framework handles the common timing pain automatically.
7. Powerful Selectors
Modern apps use nested components, iframes, and Shadow DOM. Playwright’s Locator API targets elements in a stable, readable way, including role‑based queries for accessibility. You can chain locators, filter by text, pierce shadow roots, and scope to frames.
This makes selectors resilient to CSS refactors and reduces “brittle‑selector” failures. Use roles and labels where possible, they’re more stable and improve accessibility. For complex pages, combine role/label with filter({ hasText }) or locator('.class').nth(…). Good selectors are half the battle for stable tests.
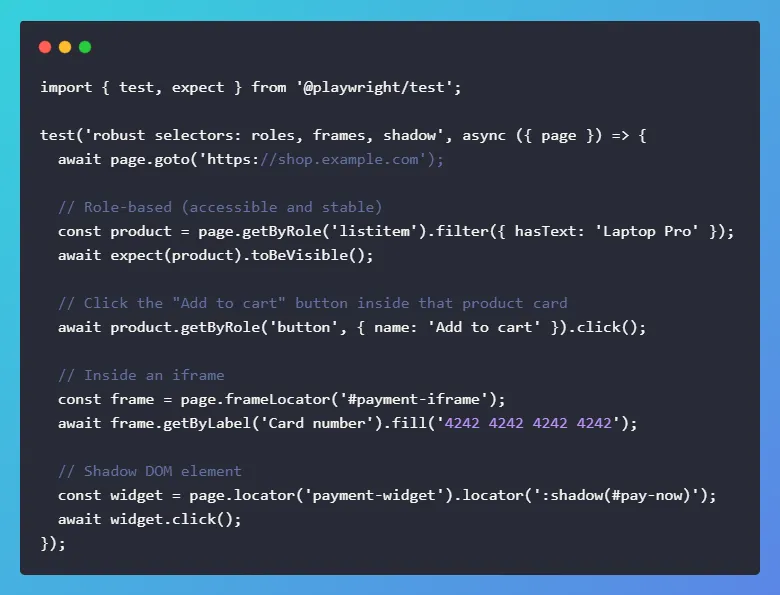
Advanced Playwright Features That Make It Stand Out in 2026
1. Codegen
Codegen records your browser actions and turns them into editable test code. It’s the fastest way to bootstrap new tests or learn stable locator patterns. You click through the flow, Playwright writes the selectors and steps.
The output is clean and uses the Locator API, so you can keep or tweak it. Use codegen to draft, then refactor into page objects or helpers. This saves time, reduces selector guesswork, and helps new contributors start quickly. It also doubles as a debugging tool. For example, record just the flaky part, compare with your current test, and merge the reliable selectors.
2. Playwright Inspector
Inspector lets you pause tests, step through actions, inspect locators, and see snapshots before/after each step. It speeds up debugging because you watch the test as it runs and fix selectors on the spot. You can enable it from the CLI or via an env var. Combine it with slowMo to watch tricky animations.
The panel shows timing, console logs, and network info, so you can spot why an assertion failed. This reduces guesswork and cuts “rerun until it passes” loops. Use Inspector while authoring, then switch back to headless for CI.
3. Trace Viewer
Trace Viewer records a full timeline of your test including DOM snapshots, network calls, console logs, steps, and screenshots. When a test fails in CI, a trace tells the story. You can replay actions, peek at the state of elements, and jump to the exact failure. Turn it on for failures only (fast) or always (deep audits).
This makes hard bugs simple as you no longer say “can’t reproduce.” You open the trace, see the DOM, confirm the selector, and fix it. It raises team confidence and reduces time spent digging through logs.
4. Network Interception & Mocking
You can intercept requests and mock responses with Playwright. This removes flakiness from third‑party services and lets you simulate errors, slow networks, and edge cases on demand. It also speeds up suites hence no need to hit real backends when the UI logic is the focus. Keep a small set of reliable fixtures for common endpoints.
For negative testing, return 500 or timeouts and verify your UI shows the right error. For complex apps, mock only what you need and allow the rest to pass through.
5. Screenshots & Video Capture
Playwright can record screenshots on demand and capture video of each test. This is great for debugging UI glitches, reporting bugs with proof, and auditing visual flows. Enable video at the context level and store it only for failed tests to save space. Pair videos with HTML and trace reports for a complete picture.
For visual checks, capture element screenshots and compare against baselines with your preferred image diff tool. The point is simple that when a test fails, you can see it.
6. Parallel Execution & Retries
Playwright runs tests in parallel workers to use all CPU cores and cut run time. It also supports retries to handle truly flaky cases while you investigate. Configure workers based on machine size, shard in CI to split the suite across runners. Use retries carefully because they mask issues if overused. A common pattern is retries: 1 and trace: 'on-first-retry' so you get a trace only when it matters. Combine with per‑project configs (Chromium/Firefox/WebKit) and you’ll get a fast, balanced CI matrix.
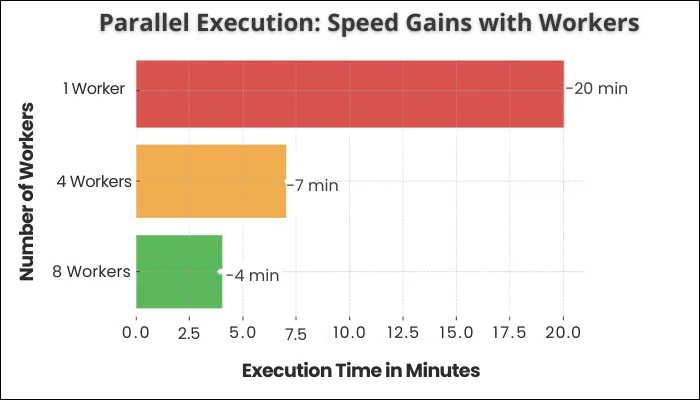
7. Built‑in Reporters & Test “Tagging”
Playwright ships with reporters (list, dot, line, HTML, JSON, JUnit). HTML is perfect for humans and JUnit/JSON for CI dashboards. You can also “tag” tests using annotations or naming conventions, then filter with --grep. Mark smoke tests, critical paths, or slow suites, and run only what you need for PRs. This keeps feedback loops fast. Add custom annotations (like issue or feature) to power team dashboards later. The goal is to focus on running the right tests at the right time.
Playwright MCP Features and Use Cases
Playwright MCP (Model Context Protocol) is the new addition. It lets AI agents control a web browser via Playwright. You tell the AI agent in plain English what to do.
For example, you can say “fill this form” or “check if this dashboard has any critical issues”, and under the hood, an MCP client sends those instructions to a server and does the task for you.
Earlier, writing browser automation scripts was hard and took time, and scripts broke when pages changed slightly. Playwright MCP makes automation more reliable, faster to set up, and easier for non-experts.
Here is a list of Playwright MCP features:
1. Accessibility Snapshots Instead of Pixels
Playwright MCP doesn’t see web pages like photos. It uses something called an accessibility snapshot, like how a screen reader sees a page: name of buttons, roles (“this is a button”, “this is a link”), etc. It makes sure the AI knows exactly what things are, not guessing by what pixels look like. So, clicking or filling in a form is more accurate.
2. Fast and Lightweight
Because it uses structured info (the accessibility snapshot) instead of heavy images or video, MCP works fast. Suppose you want to fill in a text box on a web page.
MCP can find the box by reading its role/name really quickly, rather than scanning an image, so it does it faster.
3. Reliable & Deterministic Actions
MCP interacts with page items based on their identity (role & name) rather than position on screen. That means it’s less likely to mess up if something moves slightly.
For example, if a "Submit" button moves down a bit because of a layout change, MCP still finds it because it looks for “button named Submit”, not “button at x=150, y=300”.
4. Browser Automation Tools
MCP comes with many tools that let it do things in a browser, like click buttons, fill forms, upload files, move between pages, etc. For instance, you can tell it “Go to google.com, search for ‘Playwright MCP’, click the first result.” MCP has tools that follow those steps.
5. Works with LLMs (Large Language Models)
Playwright MCP works with all the popular AI models like GPT, Claude, Gemini, etc. It can understand and use its tools easily, using simple instructions.
You can write instructions in natural language, and the MCP server will perform the tasks for you. This way you can finish hours or work in minutes.
6. Generating Tests Automatically
One feature is to ask the system to write tests. For instance: “Make a test that adds an item to a shopping cart and then checks out.” Playwright MCP helps generate that test automatically.
CLI Command
npx playwright agent --app "https://example.com"
Generated Test (Example)
import { test, expect } from '@playwright/test';
test('fills and submits form', async ({ page }) => { await page.goto('https://example.com/form'); await page.getByLabel('Name').fill('Alice'); await page.getByRole('button', { name: 'Submit' }).click(); await expect(page.getByText('Thanks Alice!')).toBeVisible();});
You give MCP those instructions, and it produces code that checks whether adding to the cart works and then purchasing works, saving you from writing every line yourself.
7. Traces, Screenshots, Debugging Support
The best of Playwright MCP is that when something goes wrong, for example, a test fails, or you want to see what’s happening in real time, it gives you tools that help you see the screenshots, trace of actions, logs inside the IDE.
For example, if a button click doesn’t do anything, you can look at a picture/snapshot of the page at that moment or see what network events or console logs happened, which helps you understand what went wrong. This way, not only do you identify problems faster, but you also understand how to fix them.
Benefits of Using Playwright
- Fewer flaky tests: Playwright waits for elements and network to be ready before it clicks or asserts. That kills many timing bugs. Locators re-resolve when the DOM changes, so your test acts like a user instead of racing the page.
Add light, explicit waits only where your app truly needs them. The result is simple. Runs pass for the right reasons and fail for the right reasons. Teams ship faster because they don’t waste hours rerunning “maybe it’s flaky” jobs. - Faster feedback at scale: Playwright runs tests in parallel workers and spins up isolated browser contexts instead of heavy new browsers.
Contexts keep cookies and storage separate, so tests don’t leak state, yet start in milliseconds. You get high CPU use, short wall-clock time, and reliable isolation. In CI, shard the suite across jobs to cut time further. Faster feedback changes team behavior as people fix issues while the code is still fresh. - Broad coverage with one API: One API drives Chromium, Firefox, and WebKit. That gives you a true cross-browser signal with minimal overhead.
Bugs that only appear in Safari or Firefox show up before users see them. Keep three “projects” in config and let CI fan out the matrix.
You can also emulate mobile devices for layout and navigation checks. You don’t need extra drivers or brittle wiring. - Faster triage with rich artifacts: When a test fails, you need proof. Playwright can capture an HTML report, a full timeline trace, screenshots, and video.
Open the trace and go through each step with DOM snapshots and network logs. You see what happened and why.
This cuts triage time from hours to minutes. Share the trace.zip in bug tickets so anyone can reproduce the failure state without guessing. - Lower maintenance cost: The Locator API targets elements by role, label, and text, which is more stable than long CSS chains. That means fewer selector rewrites after UI changes.
Start a flow with codegen to get solid locator patterns, then refactor into page objects to keep tests small and readable.
Less brittle code means fewer repairs and more time building useful coverage. - Deterministic tests with API mocking: Real services fail, rate-limit, and return odd payloads. Intercept calls and mock responses so your UI tests are fast and repeatable. Keep JSON fixtures for happy paths and error paths.
You can still allow certain routes to pass through when you want an end-to-end signal. This balance keeps the suite green during backend outages and lets you test edge cases on demand. - CI/CD-ready from day one: Playwright runs headless by default and ships with reporters for devs and machines. Tag tests to run smoke checks on each PR and full suites nightly. Export JUnit/JSON for dashboards.
Keep your feedback loop short for developers, and your coverage deep for scheduled runs. Add a single job in GitHub Actions or Jenkins and you’re live. - Works with your stack: Write tests in TS/JS, Python, Java, or .NET. Keep your team in the language they know. Playwright also fits SPA/PWA patterns.
It copes well with async UI, popups, frames, and Shadow DOM.
That means less “our app is special” glue and more direct value. You test the flows you care about without fighting the tool.
What’s New in Playwright (2026)
| Feature | Version + Date | Why It Matters | Example Snippet |
|---|---|---|---|
testStepInfo.titlePath | v1.55 (Feb 2025) | Makes debugging and reporting easier by exposing the full test hierarchy path (file → describe → test → step). Great for CI dashboards and flaky test triage. | ts\nimport { test } from '@playwright/test';\n\ntest('login flow', async ({}, testInfo) => {\n console.log(testInfo.titlePath());\n});\n// Output: ['tests/login.spec.ts', 'login flow']\n |
Automatic toBeVisible() in Codegen | v1.55 (Feb 2025) | Reduces flakiness: Playwright now inserts expect(locator).toBeVisible() automatically when recording common interactions. Less manual assertion writing. | bash\nnpx playwright codegen https://example.com\n\nRecorded output now includes:\nts\nawait page.getByRole('button', { name: 'Login' }).click();\nawait expect(page.getByText('Welcome')).toBeVisible();\n |
| Debian 13 (“Trixie”) Support | v1.55 (Feb 2025) | Ensures full compatibility of bundled browsers with Debian 13, making it safer to upgrade CI/CD pipelines without custom patches. | bash\n# Example: run tests on Debian 13 CI agent\nnpx playwright install chromium\nnpx playwright test\n |
Playwright vs. Other Tools
Below is a clear, honest comparison with a short description for each tool.
Quick comparison table
| Topic | Playwright | Selenium WebDriver | Cypress | Puppeteer |
|---|---|---|---|---|
| Browsers | Chromium, Firefox, WebKit | All major via drivers | Chromium + Firefox | Chromium only |
| Languages | JS/TS, Python, Java, .NET | Many (JS/TS, Java, C#, Python, Ruby, etc.) | JS/TS | JS/TS (community ports exist) |
| Auto-waits / retries | Built-in (Locator API) | Manual waits expected | Built-in command retries | Minimal; manual waits or helpers |
| Network mocking | Yes (route.fulfill) | Not native (use proxies/tools) | Yes (cy.intercept) | Limited (request interception) |
| Parallelism | Native in test runner | Grid / CI orchestration | Via Cypress runner / CI | DIY via Node/CI |
| Multi-tab/windows | Full support | Full support | Limited/guarded patterns | Chromium only, supported |
| Trace/Inspector | Trace Viewer + Inspector | Depends on libs | Built-in runner UI | None like PW Trace Viewer |
| Mobile | Emulation; no real devices | Real devices via Appium | Emulation; no real devices | Emulation only |
Playwright vs. Selenium
Selenium has the biggest ecosystem and works with many languages and drivers. It’s battle-tested, runs on almost anything, and pairs well with Appium for real mobile devices. The drawback is more boilerplate.
You often add explicit waits, wire reporters, and manage drivers. Playwright ships with a modern test runner, automatic waiting, cross-browser engines (including WebKit/Safari), and rich artifacts (trace, video, HTML). If you want quick, stable UI tests with less glue, Playwright is easier.
If you need real device automation or must use a niche language or vendor tool that only supports WebDriver, Selenium still fits well.
Here is the detailed comparison of Playwright vs Selenium vs Cypress
Playwright vs. Cypress
Cypress runs inside the browser and gives you a nice runner with time-travel debugging. Its command retry model is friendly, and the DX is great for front-end developers. But Cypress focuses on Chromium and Firefox; no WebKit/Safari.
Multi-tab and cross-origin workflows come with guardrails and patterns you must follow.
Playwright runs outside the browser, drives Chromium/Firefox/WebKit, supports multi-page flows, and records traces you can replay.
If your users are on Safari or you test complex auth/pop-up flows, Playwright is simpler.
If your team loves the Cypress runner and your target browsers are covered, Cypress remains a strong choice.
Playwright vs. Puppeteer
Puppeteer is a thin, fast API for Chromium automation. It’s great for scraping, PDF, screenshots, or simple UI tasks when you only care about Chrome/Edge. It’s small and familiar to Node developers.
But it’s Chromium-only. You won’t get WebKit/Safari or Firefox parity, and there’s no first-class test runner with parallelism, traces, retries, or rich reporters.
Playwright started with similar DNA, then expanded: multiple engines, Locator API, auto-waiting, powerful test runner, and integrated debugging tools. If you only need Chromium control with a tiny dependency, Puppeteer is fine. For production-grade, cross-browser testing, Playwright is the better fit.
Best Practices for Teams
Your tests should read like user stories and fail for clear reasons. The rules below keep them fast, stable, and easy to fix.
- Prefer Locators and Roles (stable, readable selectors)
Use getByRole, getByLabel, and locator() chains instead of brittle CSS/XPath. Role-based queries mirror how assistive tech sees your app, so they survive UI refactors. Chain and filter to scope precisely.
Avoid indexing (nth(3)) unless you must. Name locators as variables when reused. This makes tests self-documenting and reduces selector churn after minor UI changes. Pair roles with visible text (hasText) and labels for forms.
When you do use CSS, keep it short and resilient (data-testid works too). Good selectors are the foundation for non-flaky tests. - Use Page Objects
Keep tests short; hide page details in classes. Expose intent-level methods (login, addToCart) rather than raw clicks. This cuts duplication and makes refactors safer, update selectors in one place.
Page objects also help newcomers read tests fast. Keep them thin: no assertions inside methods unless they truly belong there. Prefer explicit waits and expectations within tests so failures point to the right step. - Reuse Setup with Fixtures
Use Playwright’s fixtures to share setup (auth, seeded data, base URLs). Fixtures reduce boilerplate and ensure every test starts from a clean, known state. Keep them deterministic and quick.
Build an auth fixture that logs in once, saves storageState, and reuses it across tests. This avoids slow, repeated UI logins and removes timing risk around auth pages. - Isolate Tests with Contexts
Each test should be independent. Use a fresh browser context per test to isolate cookies, localStorage, and cache.
Avoid sharing pages across tests. If performance is a concern, reuse the browser process but not the context. This removes “it passed locally” bugs caused by lingering sessions or mutated state. For multi-user scenarios, create multiple contexts in a single test. - Tune Parallelism and Retries
Use parallel workers to cut wall-clock time. Shard across CI jobs for big suites. Keep retries low (0–1). Retries help with rare flakes, but too many mask real issues.
Pair retries with traces only on retry to capture evidence cheaply. Mark truly slow tests with test.slow() so the runner adjusts timeouts rather than failing early. - Mock Networks for Determinis
Intermittent APIs cause flaky UI tests. Intercept calls and fulfill with fixtures for happy paths and errors. Allow pass-through for endpoints you want to exercise end-to-end. Keep fixtures close to tests and version them with the code.
Test error handling by returning 500s and timeouts on demand. This makes your suite fast and predictable. - Capture Traces, Screens, and Video
When failures happen, you want proof. Enable screenshots and video only on failure to save space. Keep traces on retry or failure.
Attach these artifacts to CI jobs so developers can open them right from the build. This cuts triage from hours to minutes. You see the DOM, network, and step timeline and fix the root cause, not the symptom. - Seed and Reset Test Data
Flaky data = flaky tests. Seed data via APIs before the UI flow. Use unique suffixes (timestamps/UUIDs) for emails and order IDs.
Clean up in afterEach/afterAll or hit a reset endpoint. Keep data creation fast; avoid long UI setup steps for fixtures. This makes tests idempotent and safe to re-run in parallel. - Tag, Filter, and Schedule: Not all tests should run on every commit. Tag smoke and critical paths. Run them on PRs. Run the full cross-browser matrix nightly. Export JUnit/JSON for dashboards. This keeps the feedback loop tight for developers while preserving deep coverage for off-hours. Failing smoke stops merges; nightly catches long-tail issues.
- Add Basic Accessibility Checks: Good selectors already push you toward accessible UIs. Add quick checks for accessible names, roles, and focus.
Use role-based assertions and verify labels. For deeper scans, integrate an a11y library in a few key flows. Even light checks catch regressions early and improve usability for all users.
Limitations of Playwright
Not every tool is perfect but knowing the exact limitations helps you plan and avoid pain.
- Heavy at scale: Parallel workers plus three engines (Chromium, Firefox, WebKit) can push laptops and small CI runners hard. Spinning too many workers causes OS thrash and random timeouts. Start modest, then tune. Use fewer workers on small runners and shard across jobs for big suites. Turn on trace/video only when needed to save I/O.
- Bigger install footprint: Playwright downloads browser binaries. That’s great for consistency, but it eats disk and slows fresh CI runs. If CI re-installs every time, jobs feel sluggish.
- No real-device mobile out of the box: Playwright emulates devices well, but it doesn’t drive real iOS/Android hardware by itself. For native apps or real device signals (camera, sensors), you need Appium or a device cloud.
- Cross-engine challenges exist: Engines differ. A CSS transition, a download flow, or a permission prompt may act slightly differently in WebKit vs Chromium vs Firefox. Some features are vendor-specific.
- Learning curve: Playwright’s power comes from fixtures, contexts, and Locator patterns. New users sometimes copy CSS/XPath from old habits and reintroduce flakiness.
- Headless debugging can feel opaque: A failing headless run without artifacts is guesswork. You need traces, screenshots, or video to “see” what happened.
- Mocking misuse can hide real issuesIt’s easy to mock everything and forget real integrations. Then production breaks on CORS, auth, or timeouts.
- Keeping versions in sync: Browsers and Playwright move fast. Random upgrades can break selectors, permissions, or timings.
Conclusion
Playwright is built for modern teams. Nobody wants a tool with lots of limitations and Playwright solves that. That’s the reason why most teams using it and even the teams used to using Selenium and other similar tools are migrating to Playwright.
However, there are some limitations of the tool which we have covered inside this post along with benefits. This will surely give you a balanced view as to whether the tool delivers on your specific expectations. If you need any help with the migration and implementing Playwright in your QA workflow successfully, please reach out to us.
Share This Article:



