How to Build an Automation Testing Strategy That Scales
Summarize With:

Gaurav Mehta
Most test automation strategies hit a wall at some point, and it almost always comes back to the same four architectural decisions. The tricky part is that most teams never actually sit down and implement them.
Things like how your tests are structured by execution time, who owns the system as infrastructure, how flakiness gets managed systematically, and how your architecture absorbs the velocity that AI-assisted development is adding to your pipeline right now.
Getting even one of these wrong is exactly how you end up where Uber did, with your engineers spending 30 to 40 percent of their time on maintenance instead of shipping, or where Atlassian did, with 150,000 developer hours consumed by flakiness.
ThinkSys has rebuilt test automation architecture across enterprise and mid-size SaaS teams long enough to know that every degrading suite has missed at least two of them. By the end of this, you will know exactly which of the four decisions your system is missing and what to do about it.
➡️ See how ThinkSys helped Boostlingo scale test automation and cut QA cycles from days to hours.
Why Most Test Automation Strategies Fail to Scale
Only 36 percent of organizations actually report positive ROI from their testing investments. The ones that do share one thing: these four architectural decisions were made deliberately, not allowed to accumulate by default.
Here's what each one is and why missing it costs more than most engineering leaders expect.
1. Test Stratification
Run The Right Tests At The Right Time
What test stratification means: Stratification is the practice of grouping tests by execution time and failure-to-fix frequency, then running each group at a different cadence - fast tests on every commit, slower tests on release branches or nightly.
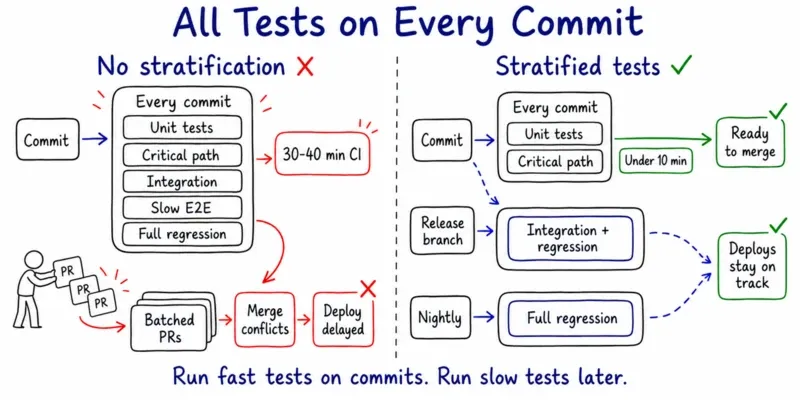
Without it, the outcome is predictable. At roughly 2000 tests with no stratification, the CI run time crosses 30 to 40 minutes. When that happens, your developers start batching pull requests to avoid waiting. Batched pull requests introduce merge conflicts and integration bugs. The suite built as a quality gate becomes the primary constraint on how often you can deploy.
This is basically the predictable outcome of running everything everywhere with no execution strategy. And a lot of teams do not realize this is happening until they are already in the middle of it.
The decision: Unit tests and critical-path integration tests run on every commit with a hard target of under 10 minutes. Full regression runs on release branches or nightly. Most teams never make this decision. They add tests until CI queues are affecting deploys, then switch tools and wonder why nothing changed.
ICST 2024 industrial case study found 2.5 percent of productive developer time disappearing to CI overhead across a large engineering organization. DORA's 2024 report found that elite performing teams deploy on demand with lead times under one day. CI reliability is basically the structural constraint separating them from everyone else.
Run this diagnostic today: Pull your last 30 CI run logs. Identify tests that run on every commit and take more than five minutes individually. Those are your stratification candidates. The goal is to have the right tests at the right execution frequency.
What ThinkSys measures before recommending any stratification change:
- CI run time at the 50th and 90th percentile over the last 90 days, broken down by pipeline stage, before recommending any stratification change
- A 90th percentile above 25 minutes on your main branch means stratification redesign is overdue
- Every test is mapped by execution time, and failure to fix frequency before tier assignment, so tests that run long and rarely catch real bugs move to nightly
FinTech note: Payment and compliance-related integration tests require guaranteed execution on every deploy. In regulated environments, stratification design must account for audit requirements, certain test classes cannot be deferred to nightly without a documented risk decision.
Stratification decides when your tests run. It does not decide who keeps those tiers intact. Without explicit ownership, the fast tier accumulates slow tests within two release cycles, and the whole architecture reverts back to where you started.
2. Test System Ownership
Give Your Test System An Owner
What test system ownership means: Test system ownership is the explicit assignment of one person or function as accountable for the test system as infrastructure, its conventions, framework health, pruning schedule, and execution strategy - separate from writing feature tests.
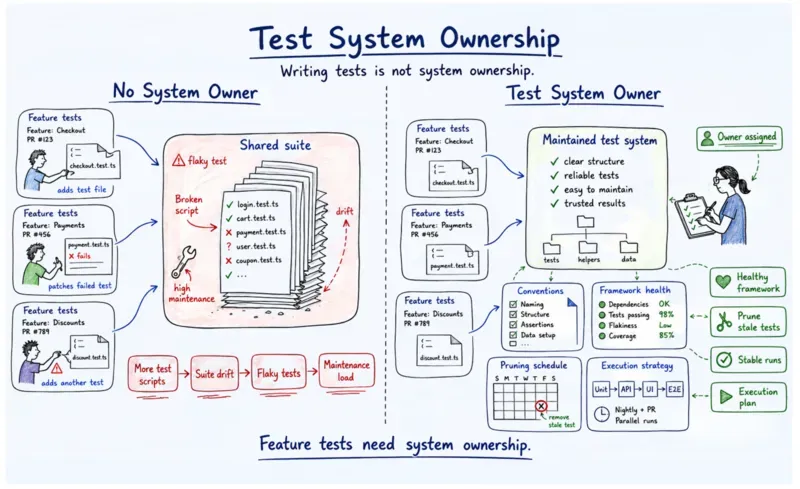
Uber's engineers were spending 30 to 40 percent of their time on test script maintenance, and the only way out was building DragonCrawl, an AI-powered tool that uses large language models to execute mobile tests and adapt to app changes automatically. That is what tightly coupled test scripts with no ownership at the system level eventually force you to do
The faster Uber shipped features, the faster the suite broke. And the fix was a new architecture that decoupled test intent from implementation details, with dedicated ownership for maintaining that decoupling. Two separate things, and a lot of teams only do one of them.
To deal with this, assign explicit ownership of the test system as infrastructure. One person or function is responsible for conventions, framework health, pruning schedule, and execution strategy. This role is separate from writing feature tests. When nobody holds it, every developer's individual good intentions compound into architectural drift, and the stratification from the previous decision degrades back toward accumulation within one release cycle.
Three questions tell you pretty quickly whether the ownership gap exists on your team right now.
- Who decides when a test gets deleted?
- Who owns the test utility and page object layer?
- Who approves changes to the test framework?
If any answer is everyone, the team, or nobody specifically, the gap is confirmed.
The organic outcome when ownership is implicit is really consistent: your team copies and pastes test code until it becomes unmaintainable and then stops testing for good. That pattern shows up in basically every post-mortem of a degraded suite.
What ThinkSys looks for to find the ownership leak fast:
- Test utility layer age is measured by the average last-modified date of helper files and duplication ratio across test files, both of which reveal the ownership gap a lot faster than any retrospective conversation
- If test deletion requires sprint grooming time to resolve, ownership is not explicit enough, and that decision should take one person under an hour
- The test system steward role gets established before any other architectural change because structural improvements revert within one release cycle without it
For healthcare and FinTech teams: Ownership of the test system intersects directly with compliance. HIPAA and PCI-DSS audits increasingly request evidence of test coverage for specific data flows. If nobody owns the system, there is nobody who can produce that evidence on request.
3. Flakiness Management and Test Data Isolation
Treat Flakiness as a Protocol
What test flakiness management means: Flakiness management is a systematic protocol, not an ad hoc investigation that defines a threshold, a quarantine process, and a fix-or-delete timeline for tests that fail intermittently.
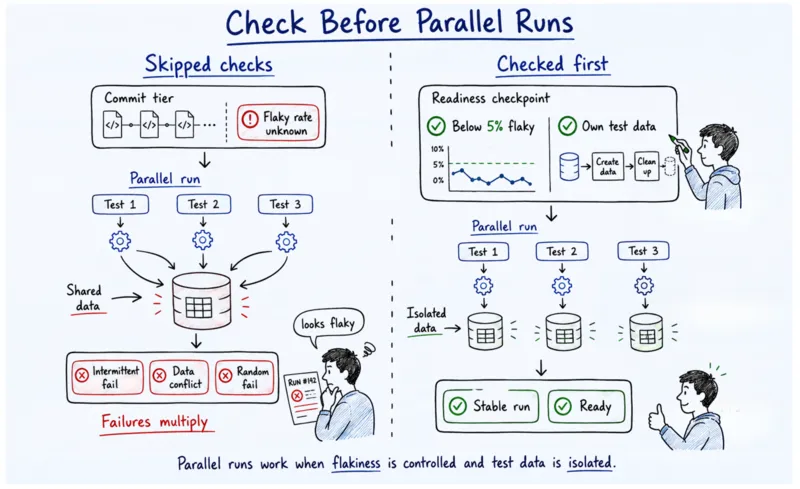
A lot of teams discover test data contamination problems after they try to parallelize. You add parallel execution in order to speed up the suite, introduce new intermittent failures, spend weeks diagnosing what looks like flakiness but is actually shared state contamination between parallel runs, and conclude that parallelization just does not work for your system. But the problem was architectural and fully predictable before you started.
The threshold: A 5 percent flaky rate in the commit tier is the action threshold. When a test crosses it you quarantine it, investigate the root cause, and delete or fix it within one sprint. Do not let failing tests accumulate. Trust, once lost, is a lot harder to recover than the tests themselves.
That threshold has to be systematic. Microsoft Research's ICSE 2020 study found that developers investigating flaky failures waste a significant amount of time on code changes unrelated to the actual failure, and that claimed fixes frequently do not reduce flakiness at all. Google still reports 16 percent of tests exhibiting flaky behavior despite dedicated infrastructure investment. If Google's research teams cannot solve this through effort alone, your 50-person team will not solve it through discipline alone.
Atlassian ran 350 million test executions per day and still accumulated 7,000 flaky tests consuming over 150,000 developer hours per year before building a dedicated internal platform called Flakinator, a dedicated infrastructure tool with explicit architectural ownership of the whole flakiness problem.
The test data isolation rule: Every test creates the data it needs and destroys it on completion. Shared test databases accumulate state across runs. When you parallelize without this in place, tests that pass individually fail in combination, and distinguishing a flaky test from a product race condition can consume weeks of diagnostic time with no clear resolution.
Before you attempt parallelization, check two things.
- Is your commit tier flaky rate below 5 percent?
- Does every test manage its own data state?
If either answer is no, parallelization multiplies existing problems.
What ThinkSys measures before touching a flaky suite:
- Flaky rate per execution tier, test setup, and teardown independence ratio measured before touching the suite structure
- Any test requiring a specific execution order to pass reliably is a test data isolation failure, not a flakiness problem, and reruns will not fix it
- Quarantine protocol established first, test data dependencies audited second, before any parallelization changes are recommended; without both, the investment is basically wasted
4. AI Velocity Management
Account For How AI Is Widening Your Architecture Gap Right Now
What AI velocity management means in testing: AI velocity management is the practice of tracking the ratio of new code production to QA infrastructure capacity, and adjusting the test architecture before the gap between them becomes a maintenance crisis.
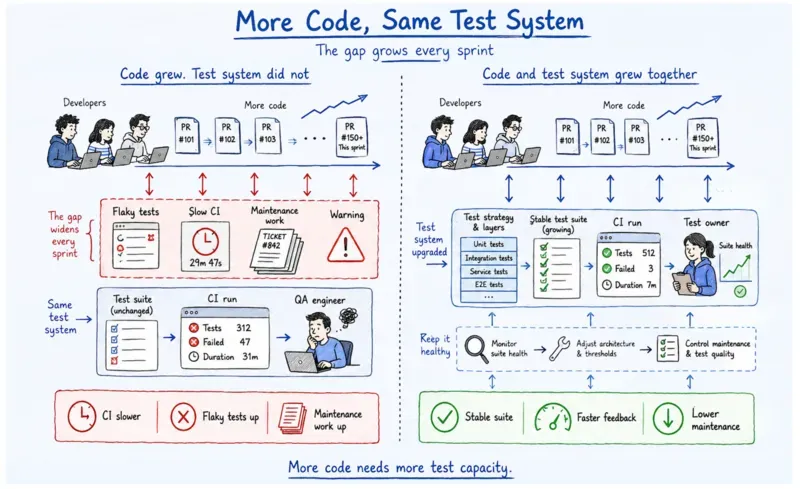
DORA's 2024 report found that AI-assisted development boosts individual developer productivity while reducing software delivery stability. It is the condition already measured in teams using these tools right now. Faster code production, same test infrastructure capacity, growing gap between the two, every sprint.
The Bitrise Mobile Insights 2025 report analyzed over 10 million builds and found that the share of teams experiencing flakiness grew from 10 to 26 percent between 2022 and 2025, a 160 percent increase as CI pipelines grew 23 percent more complex.
AI coding tools are feeding code into a test infrastructure that was never designed to absorb that velocity. The maintenance overhead from the previous decisions grows faster.
The flakiness surface area expands faster. And your team is probably already seeing this, even if nobody has actually named it yet.
The cost is calculable: ICST 2024 found 2.5 percent of productive developer time consumed by CI overhead. For a 50-engineer team at 160,000 dollars fully loaded, that is roughly 200,000 dollars a year in direct CI waste. Apply Uber's disclosed maintenance overhead of 30 to 40 percent to a 5-person QA function at 130,000 dollars fully loaded, and you get 195,000 to 260,000 dollars per year on maintenance alone. Combined, that is 300,000 to 400,000 dollars or more for that team profile.
This architecture determines whether your suite survives the next 12 months of AI-accelerated growth. The question is whether you make these decisions before the next growth phase or after the next production incident.
What ThinkSys tracks before advising any architecture change:
- Ratio of new test creation to test maintenance in the last 90 days. If maintenance outpaces creation, the AI velocity gap is already active in your pipeline
- Developers shipping code at 1.5 times or more their pre-AI velocity without a proportional increase in QA capacity is a confirmed gap signal
- Maintenance-to-creation ratio tracked as a leading indicator before any architecture change is advised, it distinguishes a stable gap from an accelerating one
The Decision That Determines How Long This Takes To Fix
Atlassian built Flakinator. Uber built DragonCrawl. Microsoft built an organization-wide flaky test management system covering 49,000 identified flaky tests. The common thread is not their tooling. Every organization that successfully addressed test automation at scale stopped treating the test system as background work and assigned dedicated architectural ownership to it.
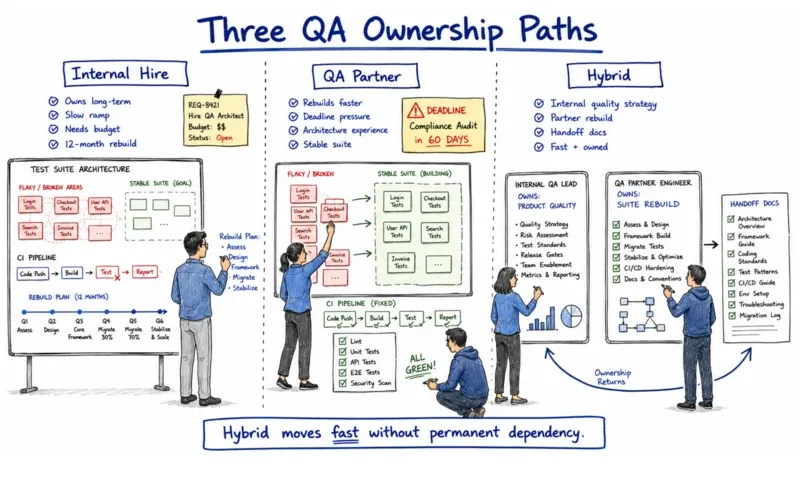
Three realistic paths exist for your team, and each has honest tradeoffs.
- Internal QA architect hire: Right, if your team is above 80 engineers, you have a headcount budget, and you can absorb a 12-month architecture rebuild timeline without business pressure forcing shortcuts. This path gives you permanent internal ownership, but it is really the slowest to show results and the hardest to execute well if your internal team has not actually rebuilt a degraded suite before.
- Specialist QA partner: It works if your rebuild timeline is compressed by a funding round, compliance deadline, or degradation already past two of the four thresholds. Also, if your internal team lacks the architectural experience to know what a fixed suite actually looks like, which is more common than most CTOs say out loud. ThinkSys works this way with clients who need the architecture rebuilt without losing a product cycle in the process.
- Hybrid model: Your internal QA lead owns product-area quality strategy, while a specialist partner owns the architecture rebuild for the first 12 months, then hands off with documented conventions. This is the model we recommend most often for mid-size SaaS teams that have the internal talent but not the bandwidth to run a full rebuild alongside normal product delivery. It basically moves fastest without creating a permanent dependency.
To make the right decision, run the four-question diagnostic. Bring the numbers to your next engineering leadership meeting with one question:
Who owns each of these thresholds right now?
If the answer is unclear for any of them, you have confirmed the ownership gap. That is where to start. Not with a tool evaluation, coverage audit, or vendor conversation.
Conclusion
The biggest risk to your test automation is not that you have too few tests.
It is that you have a test system built for an earlier version of your product, one that assumed slower code velocity, simpler data dependencies, and more patience for slow feedback. And when it breaks, it breaks in both directions at once, too slow to support your deployment cadence and too unreliable to catch the failures that actually matter.
A QA model that cannot answer those four questions confidently means that it was never designed for where your product is heading. The teams that close this gap without losing a product cycle are the ones that bring in people who have rebuilt this architecture before and give them the ownership mandate to finish the job.
If you are not sure which decision your system is most overdue on, that is exactly where a ThinkSys test automation audit starts. Four metrics. A clear read on where you actually are. A rebuild plan that doesn't pause your product roadmap to execute.
Book a Free Test Automation Audit
Response within one business day. No sales call required to get the audit findings.