QA Strategy for CI/CD Pipelines: A CTO's Guide
Summarize With:

Harsh Goel
Most engineering teams follow the same QA playbook. Write tests. Track coverage. Keep the pipeline green. Ship when the numbers look right.
Cloudflare and CrowdStrike followed it too. You know how that ended.
The instinct after a release failure is predictable. More tests, stricter coverage thresholds, more QA headcount. These are volume answers to what is actually a structural problem. Your pipeline is not catching the failures that matter because it was never designed to.
Working across enterprise and mid-size SaaS engineering teams, ThinkSys identified a consistent pattern in where pipelines actually break down and what controls, placed at what stage, prevent it.
That work became a four-stage framework that is now the foundation of how we rebuild QA for every client we work with.
This guide walks through each stage, what breaks without it, and exactly what to put in place.
How Healthy Is Your Pipeline?
Add up every Yes and Not Sure answer. Not Sure counts as a risk because if you cannot answer confidently, the gap likely exists.
Score 0: Every answer was a confident No. Your pipeline is in good shape, and the framework below will sharpen it further.
Score 1 to 2: You have gaps, and they are quietly compounding. The framework below will show you exactly where.
Score 3 or more: Your pipeline is a structural liability, and more tests will not fix it. The framework below will.
The Four-Stage Framework: Where Every Category of Risk Actually Belongs
Different categories of risk need to be caught at different stages of your pipeline, and catching them at the wrong stage either misses them entirely or makes your pipeline too slow and noisy to trust.
We developed this framework through repeated work with engineering teams where the same structural gaps kept appearing across different companies, different stacks, and different release cadences. What follows is exactly how we implement it for our clients.
Stage One: Pre-Merge Validation
(Stop The Obvious Failures Before They Ever Reach The Team)
Shopify documented what a slow, noisy pre-merge stage actually produces, which is engineers who stop trusting the pipeline and start discounting every failure. It happens because overloading pre-merge feels like thoroughness from the inside. The pipeline keeps running, but your team has already quietly opted out of it.
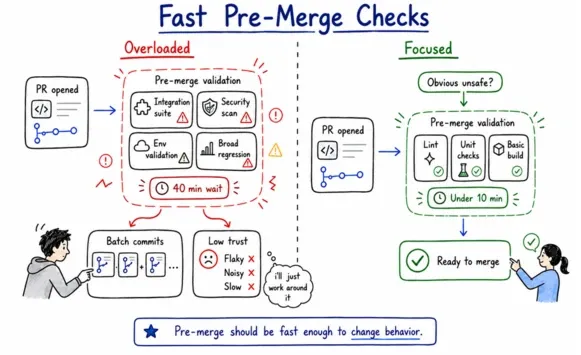
Teams push integration checks, security scans, environment validation, and broad regression suites into pull request gates because it feels safer. What you end up with is a gate that takes 40 minutes to clear on a routine change, developers who batch commits to avoid waiting, and a feedback loop so slow it stops changing behavior. The stage that was designed to catch obvious failures becomes the stage that teaches your engineers to work around the pipeline.
The other failure mode is the opposite. Pre-merge gates that are too shallow pass trivially, while real issues slip through to later stages, where they are far more expensive to catch.
Pre-merge validation has one job, which is to answer whether this change is obviously unsafe to combine with the mainline. That is a narrow question, and it should be answered fast, under ten minutes for most codebases.
How ThinkSys builds it for its clients
When we rebuild a client's pre-merge stage, we scope it to the checks that are both fast and high-signal. Everything else gets moved to the stage where it actually belongs.
- Unit tests scoped to changed components only, not the full suite
- Static analysis and linting with failure thresholds that reflect real risk, not style preferences
- Contract tests for any service boundary touched by the change
- Security policy gates are limited to critical vulnerability classes
- Execution time target is set as a hard constraint, so if a check cannot meet it, it moves downstream
- Flaky test identification and quarantine are treated as ongoing maintenance work, not a quarterly cleanup
Stage Two: Pre-Deploy Validation
Catch What Code Reviews And Unit Tests Were Never Designed To See
Most pipelines treat pre-deploy validation as an extension of pre-merge testing, just more of the same checks with a slightly broader scope. That completely misses the point of this stage. Code correctness and system readiness are two different questions. A change can be functionally correct and still fail in deployment because of a configuration mismatch, a missing secret, an incompatible dependency, or a migration that does not account for the current state of your production database.
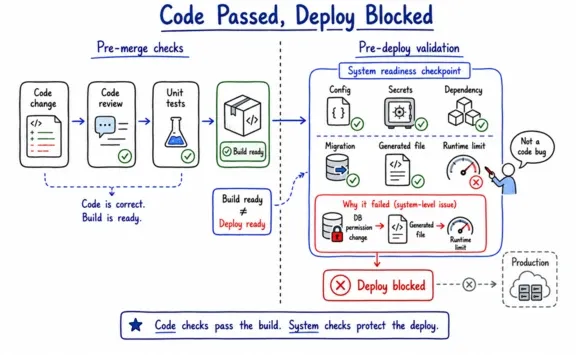
Cloudflare's November 2025 outage is a good example of what lives in this gap. A database permission change altered the output used to generate a feature file for Bot Management. That output exceeded a runtime limit on the number of machine learning features the system could load. The code was correct, but the interaction between a configuration change, a generated artifact, and a runtime constraint was not validated anywhere in the pipeline.
Pre-deploy validation answers a different question than pre-merge. It asks whether your system is ready to receive this change. That means validating your environment, your configuration, your dependencies, and your deployment mechanics, not just the code itself.
How ThinkSys approaches this step
- Integration tests that reflect actual service interactions in a staging environment, not mocked approximations
- Database migration dry-runs with rollback verification before every deployment
- Environment configuration checks that compare the expected and actual state explicitly
- Secrets and credential validation to confirm they are present, correctly scoped, and targeting the right environment
- Deployment manifest validation, where parameters, targets, and environment flags are verified programmatically before execution
- Dependency compatibility checks across the full dependency graph, not just direct dependencies
- Artifact integrity verification to confirm that what you are deploying matches what was built and signed
Stage Three: Progressive Delivery
Contain What Still Gets Through
Most in-house QA strategies treat deployment as a binary event. The change either goes out or it does not. There is no middle ground, no graduated exposure, and no way to catch a failure that only surfaces under real production load before it reaches every user. When something escapes pre-deploy validation, and eventually something will, the blast radius is your entire user base.
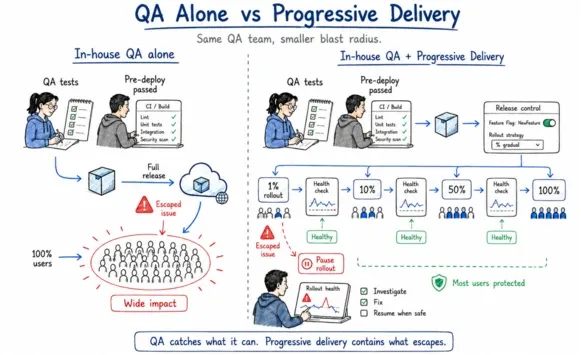
This is the stage where most mid-size SaaS engineering teams have the biggest gap. Not because the tooling is hard to access, but because progressive delivery requires deliberate pipeline design, and it never gets prioritized until something goes wrong.
Progressive delivery accepts that your pre-production confidence is never complete and builds release controls that contain the cost of being wrong. The goal is not to replace your earlier validation. It is to make sure that one escaped defect cannot become a company-wide event.
Spotify's staged rollout model exists for exactly this reason, which is to make sure one escaped defect reaches one percent of users instead of all of them. Without this stage in your pipeline, every single deployment is an all-or-nothing bet.
How ThinkSys handles this
We build progressive delivery into your release pipeline as a first-class control. For clients without any progressive delivery infrastructure, we start with the controls that deliver the most blast radius reduction immediately and build from there.
- Feature flags for all significant changes, so you can disable instantly without a redeployment
- Canary releases that expose changes to one to five percent of traffic before full rollout
- Automated promotion gates tied to error rate, latency, and business-critical flow metrics rather than time elapsed
- Explicit rollback triggers are defined before deployment begins, not after an incident starts
- Dark launches for high-risk changes so you get full production load with zero user visibility and real signal
- Staged rollout percentages with defined hold periods between each increment
- A clear decision framework that distinguishes pause from rollback from full abort
Stage Four: Production Verification
Let Production Tell You What Everything Else Missed
Production monitoring gets treated as an operations concern rather than a QA concern. Alerts fire when something is obviously broken, and post-mortems happen after the incident. But the feedback loop from production back into your release process is rarely closed deliberately, and that means the same categories of failure can keep recurring across multiple releases before your pipeline gets updated to catch them.
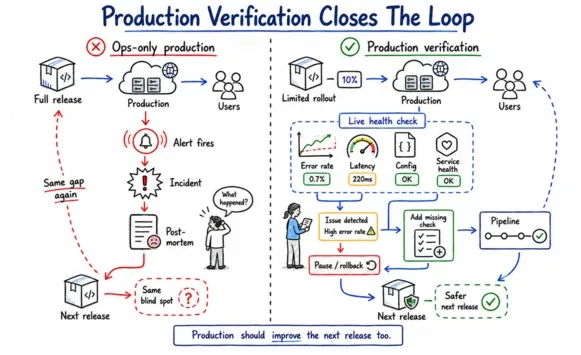
Google makes this point directly in Software Engineering at Google. Even with one of the most mature testing cultures in the industry, configuration changes remain their number one cause of major outages. They run thousands of chaos and resilience tests every week, not because their pre-production validation is weak, but because production reveals failure modes that no pre-production environment fully replicates.
Production verification closes the feedback loop. It treats production not just as where your software runs, but as the final and most honest source of quality signal you have. The goal is to use that signal to make release decisions in real time and improve your pipeline coverage over time.
ThinkSys’s way of building it
- Crash rate and error rate thresholds are configured as automated rollback triggers, not just alert thresholds
- Service level health checks running continuously against business-critical flows, not just infrastructure metrics
- Synthetic transaction monitoring for your highest-value user journeys
- Anomaly detection on key business metrics like conversion, activation, and retention as a release quality signal
- A structured post-deploy review process that feeds escaped defect patterns back into earlier pipeline stages
- Resilience exercises on a scheduled cadence to surface assumptions baked into your system before they surface in an incident
- Incident classification by pipeline stage of origin, so your team knows not just what broke, but where in the control system it was supposed to be caught
The Pipeline That Protects Speed Instead Of Fighting It
The biggest risk to your CI/CD pipeline is that you have a QA model designed for an earlier version of your company, one that assumed fewer releases, simpler configuration, and more patience for slow feedback. That model holds until it does not. And when it breaks, it breaks in both directions at once, too slow to keep up with your team and too shallow to catch the failures that matter most.
The four-stage framework exists because we have seen this pattern across enough engineering teams to know that the fix is structural. Fast checks before merge. System validation before deployment.
Progressive controls during rollout. Hard feedback from production after release.
Each stage catches a different category of failure, and together they produce something a coverage dashboard never can, which is a pipeline your engineers trust, your releases depend on, and your business can scale with.
If you are not sure which stage your pipeline is weakest in, that is exactly the conversation a ThinkSys QA audit is designed to start. We’ll show you where the highest-leverage changes are and what it would take to make them.
If your team ships fast but still gets surprised by production failures, that's exactly what we fix.