10 Critical Enterprise Software Test Cases + QA Metrics for 2026
In enterprise software, skipping even a single test can cause more trouble than most teams want to imagine.
Knight Capital learned that the hard way losing $440 million in just 45 minutes. Not because they didn’t have talent on the team. They did. But because a few tests slipped through the cracks.
And that’s the thing. Every industry you can think of automotive, healthcare, finance runs on enterprise software now. It keeps things moving, cuts costs, keeps productivity up. But it only works if the software is tested thoroughly, and not just once. Often. Relentlessly.

If you miss the right tests, the fallout can be brutal.
Financial disaster: In 2021, Mission Produce, a global avocado supplier, rolled out a new ERP system. It couldn’t reliably track inventory, spoilage, or ripeness. So they were forced to buy avocados at full market price just to meet demand. The losses? Millions.
Operational breakdown: In 2022, a single bad Microsoft Teams update caused hours of downtime across the globe. Entire teams suddenly found themselves… waiting. Staring at screens. Meetings stalled. Work stalled.
Bugs, crashes, and shaky features don’t just frustrate people. They bleed money. They slow everyone down. They erode trust—fast.
Here’s the reality: testing isn’t “QA’s job” anymore. It’s everyone’s job. From the very first commit to the moment you hit release.
When you test early and test often, you don’t just catch the obvious stuff—you stop the quiet, sneaky issues before they snowball. You keep systems stable. You keep them secure. And you keep the door open for real growth.
This guide covers 10 critical test cases for enterprise software that every QA team should prioritize to ensure stability, security, and peak performance before launch. For each one, you’ll see:
- Why does it matters to the business?
- What to test, technically?
- The best tools and metrics to use?
If you’re a CTO, QA lead, or product owner, think of this as your roadmap to building software people can trust—and keep trusting.
Why Robust Testing Matters for Enterprise Software
Imagine this it’s 9:02 a.m. on a Tuesday. Your team logs in for the weekly status meeting—except the video platform won’t load. Messages won’t send. Your project deadline is today, but suddenly, the one tool your whole company relies on is gone.
That’s exactly what happened to thousands of businesses in 2022 when Microsoft Teams went down. A single misconfigured update—skipped over in rollback and integration testing—triggered a global outage. Hours of productivity, gone. Deals delayed. Meetings missed. And the worst part? There was no quick fix, no plan B.
Must Read: QA Strategy for Enterprise Software
Enterprise software is like that.
It’s invisible when it works, but the second it fails, everyone feels it. It runs supply chains. Processes payroll. Guards sensitive data. Keeps companies compliant with rules that can cost millions if broken.
When it breaks, the damage is instant. Deadlines slip. Customers get frustrated. And sometimes, the financial hit comes fast—millions lost in hours.
And here’s the uncomfortable truth: even the biggest companies, with deep pockets and whole teams dedicated to quality assurance, aren’t immune. If testing doesn’t go deep enough, something will slip through.
Why Traditional Testing Falls Short
Most teams do test their software. But the problem isn’t the presence of testing—it’s the scope.
The standard checklist usually looks like this:
- Verify core features work (functional testing)
- Check the UI behaves under normal use
- Run a few manual or semi-automated tests before release
That’s fine for a mobile app or small tool. But enterprise systems? Completely different story.
They’re hooked into APIs, third-party tools, and—often—decades-old databases still running in the background. They operate across hybrid or multi-cloud setups. And they don’t just have to work—they have to meet strict security, compliance, and performance SLAs.
A basic test can tell you if a button works.
It won’t tell you if it still works when 10,000 people click it at once… or when the connected API crashes… or when the backup system has to take over mid-operation.
That’s why so many “fully tested” enterprise systems still crash in production. The easy stuff made it into the test plan. The messy, unpredictable, real-world chaos didn’t.
Traditional vs. Enterprise Test Cases — What’s the Difference?
Picture this: it’s quarter-end. Orders are flying in, the finance team is closing the books, and your ERP system freezes mid-transaction.
Support scrambles. IT tries a quick restart. Customers are still waiting. Every minute costs more than you want to think about.
That’s when you realize: the feature worked fine in testing. But the business didn’t survive the failure.
And that’s the real difference.
For everyday software, testing is mostly about making sure something works as expected.
For enterprise systems, it’s about making sure the business stays operational under pressure, under load, and in the middle of real-world chaos.
Here’s how enterprise test cases push beyond the basics:
| Dimension | Traditional Test Cases | Enterprise Test Cases |
| Focus | Confirms a feature works. | Ensures the business keeps running and SLAs are met in messy, unpredictable conditions. |
| Environment | Runs in a single, stable setup. | Runs in distributed, hybrid-cloud environments, ready for failover and disaster recovery. |
| Data Scenarios | Uses small sets of mock data. | Uses high-volume, realistic datasets with many users hitting the system at once. |
| Integration Level | Tests only at the app layer. | Tests across services, systems, and vendors—where most enterprise failures actually happen. |
| Security | Basic checks like login/logout. | Full security sweeps: RBAC, audit logs, encryption, token expiry, compliance validation. |
| Stakeholder Impact | Mainly affects dev and QA. | Affects operations, finance, legal, compliance, customer service—everyone. |
In short: traditional tests confirm the app works. Enterprise tests confirm the business survives.
Why Critical Test Cases Matter in Enterprise QA
You don’t always know a test case is critical… until it’s the one you skipped.
Picture it: a customer tries to check out, but the payment gateway times out. Or your login API fails on a Monday morning when the entire sales team is trying to start their day. Or worse an unnoticed security gap leaks sensitive client data before anyone spots it.
Some test cases can wait. Others if missed can lead to outages, breaches, or entire business operations grinding to a halt. Those are your critical test cases.
And you don’t identify them by gut feeling. You find them by looking closely at where enterprise systems tend to break.
Where Critical Failures Hide
- Integration Weak Spots: Enterprise software is a web of modules, APIs, and third-party tools. That’s a strength… until one stops talking to the others. If your payment gateway, CRM, or legacy database goes silent, entire workflows can stall.
- Security Gaps: These systems often store sensitive business and personal data. One overlooked vulnerability can turn into a breach, lawsuits, or costly compliance violations.
- Maintenance Bottlenecks: After launch, updates and fixes take time—and sometimes more time than the team can spare. If knowledge is siloed or staffing is thin, even a small bug can quietly grow into a stability nightmare.
How QA Teams Decide What’s Critical
The best QA teams don’t give every test equal weight. They rank them based on risk and business impact:
- Business Continuity Impact – If failure stops core operations—payments, logins, data sync—it’s critical.
- High Likelihood of Production Failure – Prioritize based on post-mortems, outage history, and known weak points.
- Integration Dependencies – Anything tied to APIs, third-party systems, or vendors needs extra scrutiny.
- Security, Compliance, and Legal Risk – If failure could mean a breach, audit failure, or fine, it’s on the critical list.
- Performance Under Stress – Load testing, failover drills, and recovery scenarios for traffic spikes or crashes.
Bottom line: a critical test case is one where failure costs you money, trust, or compliance—sometimes all three at once.
How to Shortlist the Most Critical Test Cases
In a big enterprise project, you can easily end up with hundreds—sometimes thousands—of test cases in your suite.
But here’s the thing: not all of them matter equally. Some are nice-to-have. Others, if skipped, can take down your business in a single afternoon.
The best QA teams don’t guess. They use a clear, repeatable filter to figure out what’s truly critical.
The Critical Test Case Filter
- Direct Business Impact: If this function fails, does it stop the company in its tracks?
Examples: payment processing, login flows, customer data updates. If any of those go down, you’re not just fixing bugs—you’re losing money by the minute. - Proven High-Risk Areas: Look at outage reports, bug histories, and post-mortems.
Patterns emerge. Some areas have already caused pain. Those spots go straight to the top of the list. - Integration Sensitivity: Anything connected to external APIs, vendor tools, or legacy systems.
They’re fragile. They change without warning. And they often break when you least expect it—especially after updates. - Security, Compliance, and Legal Exposure: Could this failure cause a data breach, trigger an audit failure, or rack up regulatory fines?
If yes, it’s critical by default. No discussion needed. - Performance Under Pressure: Functions that have to keep running during peak load, failover, or recovery scenarios.
Think flash sales, end-of-quarter rushes, or unplanned server crashes.
Think of a critical test case like the main support beam in a skyscraper.
If it fails, the whole structure is at risk—no matter how polished the rest of the building looks.
10 Critical Test Cases Your Enterprise Software Must Pass(with Examples)
Now, let’s take this filter and apply it to the 10 non-negotiable test cases every enterprise system should pass before launch—starting with the foundation of everything: Data Integrity.
1. Data Integrity Across Operations
Data is the lifeblood of any enterprise system.
If it’s wrong, everything that comes after is wrong too—forecasts, invoices, compliance reports, all of it. The UI might look sharp. The APIs might be lightning-fast. But if they’re serving up bad data? You’re just making bad decisions faster.
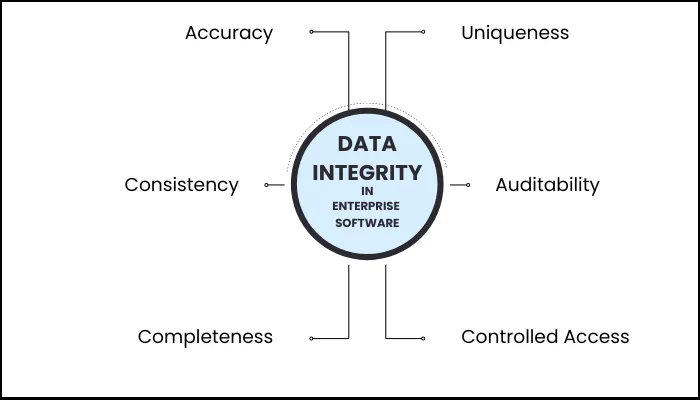
I’ve seen it happen. One system says a customer lives at 45 West Street, another says 54 West Street. Not a huge deal, right? Until the wrong invoice goes out. Or the shipment gets bounced. Or finance spends two days reconciling the mess while everyone else is waiting on them.
And if you’re in a regulated industry, that “minor mismatch” can show up in an audit… and suddenly it’s not just a cleanup job—it’s a fine or a formal investigation.
Why It’s Critical
- Tiny discrepancies ripple into billing errors, compliance issues, and wasted man-hours.
- In some industries, incorrect data is more than a nuisance—it’s a liability.
What to Test
- Data migration from legacy systems – Moving old records into the new world without breaking them.
- Accuracy after failover or disaster recovery – Making sure “recovered” doesn’t mean “corrupted.”
- Cross-module data replication – One record, one truth, across every module.
- Report accuracy – Because leadership will make decisions based on them—whether they’re right or wrong.
- Transaction consistency in multi-step workflows – From start to finish, the data should tell the same story.
Techniques That Work
- Database Assertions – Verify the values stored are exactly what they should be, every time.
- Workflow Testing – Follow the path a real user (or system) would take, across modules.
- Reconciliation Testing – Compare records after syncs or migrations to spot silent mismatches.
Pro Tip: Skip the perfect, “happy path” test data. Use the messy, oversized, typo-ridden datasets that look like what you actually see in production. That’s where the real bugs hide.
Sample Test Case
| Test Case Name | Validate the synchronization of customer addresses between the CRM and billing systems to ensure accurate data. |
| Objective | Ensure that address updates in the CRM are accurately reflected in the Billing system. |
| Preconditions | A valid customer must exist in both systems and must have edit and query access. The sync service should be active. Systems should be online and connected. |
| Steps | 1. Update a customer's address in the CRM. 2. Trigger synchronization workflow. 3. Query the billing database to retrieve the address. 4. Compare the values with the CRM database. |
| Expected Results | The customer's address should be updated in both the CRM and billing systems without loss or corruption. |
| Severity | High |
| Tools | Postman, SQL Developer, Apache JMeter. |
2. Load Handling at Peak Business Hours
Speed. Stability. Scalability.
Those three words decide whether your enterprise system glides through peak demand… or collapses in front of everyone.
And “load” isn’t just about how many people visit your website. It’s everything hitting the system at once—API calls, concurrent transactions, background jobs, data processing queues, batch imports and exports. Real life is rarely one thing at a time.
Why It’s Critical
Every enterprise has pressure points—moments when the whole business is watching the clock:
- Quarter-end financial closings
- Payroll days
- Flash sales or seasonal traffic spikes
- End-of-day batch processing
If the system slows down in those moments, you feel it immediately. Lost revenue. Delays that throw off entire departments. Frustrated customers. And sometimes, the embarrassment of explaining to the public why you weren’t ready.
I’ll never forget the 2020 Australian Taxation Office outage. Tax season. Millions trying to log in. And because realistic load tests hadn’t been done, the system crumpled. Worst possible time, zero room for excuses.
What to Test
- API throughput and latency under heavy concurrent requests
- Database performance when write loads spike
- Background job speed and queue stability under sustained demand
- Frontend responsiveness with thousands of active users
- Graceful degradation—does it slow down intelligently or just fail.
Techniques That Work
- Load Testing – Gradually ramp up demand until you see the first cracks.
- Stress Testing – Push it past its limit to find the breaking point.
- Soak Testing – Keep it under heavy load for hours or days to see what leaks or drifts.
- Spike Testing – Drop a sudden traffic surge and watch the recovery.
- Baseline Benchmarking – Record the “normal” so you know when you’re drifting off course.
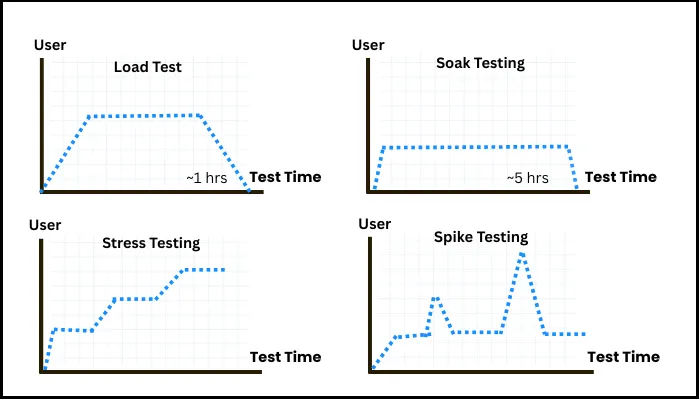
Pro Tip: Don’t test in perfect silos. In production, API surges, background jobs, and batch processes collide. Recreate that chaos—because that’s the load your system will really face.
Sample Test Case
| Test Case Name | High-traffic load simulation during peak business hours. |
| Objective | Validate system stability and performance during high-traffic business hours. |
| Preconditions | The application environment should replicate the production environment, and monitoring tools must be properly configured. Test data and user credentials should be preloaded. |
| Steps | 1. Use JMeter to simulate 5000 concurrent users logging in and performing purchase transactions. 2. Monitor CPU, memory, and database connection pool. 3. Capture API response times and error rate. 4. Monitor backend queue processing. |
| Expected Results | - 95th percentile response time < 3 seconds. - Error rate < 0.5%. - No CPU or DB saturation. - All messages processed within 5 seconds. |
| Severity | Critical |
| Tools | Apache JMeter, Grafana, New Relic or Datadog, and ELK Stack. |
3. Security Vulnerability Assessment & Penetration Testing
If your enterprise system is the vault of your business, security testing is you trying to break in—before someone else does.
Because here’s the reality: security isn’t optional. You can recover from a bug. You can patch performance issues. But one missed vulnerability? That can mean stolen customer data, regulatory fines, and a reputation that takes years—sometimes decades—to rebuild.
Why It’s Critical
Enterprise systems are prime targets. They store the kind of information attackers dream about—financial records, personal identities, intellectual property. And with multiple modules, complex permission layers, third-party APIs, and cloud components, there are more doors and windows to check than you think.
All it takes is one:
- A poorly sanitized input field vulnerable to SQL injection.
- A misconfigured API endpoint.
- A role-based access control that isn’t quite as strict as you thought.
That’s the open door an attacker needs.
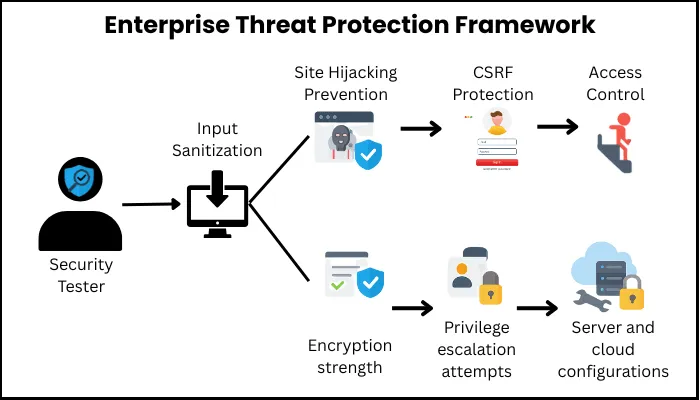
What to Test
- Input sanitization – Block SQL injection and XSS attacks at the source.
- Session hijacking prevention – Make stolen cookies useless.
- CSRF protection – Stop cross-site request forgery attempts cold.
- Access control – Lock down endpoints and APIs to the right roles only.
- Encryption strength – Keep data safe both in transit and at rest.
- Privilege escalation attempts – Verify users can’t “accidentally” promote themselves.
- Server and cloud configurations – Close the gaps attackers exploit most often.
Techniques That Work
- SAST (Static Application Security Testing) – Scan your source code before it even runs.
- DAST (Dynamic Application Security Testing) – Attack the running app to find live vulnerabilities.
- IAST (Interactive Application Security Testing) – Combine SAST and DAST for deeper coverage.
- Penetration Testing – Bring in ethical hackers to think like the real thing.
- Threat Modeling – Map likely attack paths and prioritize defense.
Pro Tip: Automated scans are great for finding known issues. But the clever, unexpected exploits? Those are found by humans thinking creatively—exactly how attackers operate. Use both.
Sample Test Case — SQL Injection on Login
| Field | Details |
| Title | Validate resistance against SQL injection on the login form |
| Objective | Ensure login inputs are secured against SQL injection attempts. |
| Preconditions | - App is deployed in a test environment - Test user credentials exist - Logging is enabled (application + web server) |
| Steps | 1. Open the login page. 2. Enter '1'='1 as both username and password. 3. Click Login. 4. Observe UI behavior and HTTP status/response. 5. Review web server and application logs for intrusion/audit events. 6. Run a DAST scan against the login endpoint. 7. Verify queries are parameterized/sanitized. 8. Check backend logs to confirm no unauthorized SQL executed. |
| Expected Results | - Injection attempts fail with a generic error or standard login failure. - No DB error details exposed in the UI. - Payloads do not alter backend behavior or execute. - All attempts are logged (IP, payload, timestamp) and flagged as suspicious. - No unauthorized access or data leakage occurs. |
| Severity | Critical |
| Tools | OWASP ZAP, Postman, Wireshark, Splunk, SQLMap. |
4. Responsiveness & Accessibility Compliance
Enterprise software has to work for everyone—on any device, any screen size, and regardless of ability.
That means:
- A dashboard should feel just as natural on a 27" monitor as it does on a 6" mobile screen.
- A visually impaired employee should be able to navigate the entire system with a screen reader.
- Touch targets on mobile should be big enough that users aren’t zooming in or missing buttons.
It’s not just about “good UX.” It’s about meeting legal requirements like WCAG and ADA, and ensuring every single person in the organization can use the software effectively.
Why It’s Critical
Poor responsiveness slows people down. It frustrates teams who just need to get work done.
Lack of accessibility goes further—it excludes employees, limits adoption, and in some cases, triggers lawsuits.
What to Test
- Layout behavior – How does the interface adapt to different screen sizes and orientations?
- Mobile navigation – Is it smooth, intuitive, and touch-friendly?
- Screen reader compatibility – Are ARIA labels accurate and meaningful?
- Text resizing and zoom – Does the layout hold up without breaking?
- Touch target size & spacing – Are they usable without precision clicking?
- Assistive tech support – Does the software play nicely with common tools?
Techniques That Work
- Simulation – Quickly check many devices using browser/device simulators.
- Emulation – Recreate platform-specific behaviors for more realistic results.
- Real Device Testing – Nothing beats seeing it on the actual hardware.
- Automated Testing – Build accessibility and responsiveness checks into CI/CD so they never get skipped.
Pro Tip: Accessibility isn’t just compliance—it’s about ensuring every employee can contribute without barriers. That’s both a moral win and a business win.
Sample Test Case — Screen Reader Navigation
| Field | Details |
| Title | Validate screen reader navigation on the main dashboard |
| Objective | Ensure visually impaired users can navigate the dashboard using a screen reader. |
| Preconditions | - NVDA screen reader installed - Application deployed and accessible in Chrome |
| Steps | 1. Launch NVDA. 2. Open the dashboard in Chrome. 3. Use arrow/tab keys to navigate. 4. Listen to the screen reader output. |
| Expected Results | - All elements read aloud in correct order. - ARIA labels accurate and descriptive. - No unlabeled buttons or links. |
| Severity | High |
| Tools | NVDA, Axe DevTools, Google Lighthouse |
5. Authentication & Role-Based Access Control (RBAC)
In enterprise software, the biggest mistake you can make is letting everyone see—or change—everything.
That’s why we have Role-Based Access Control, or RBAC. It’s the difference between handing someone a key to their office… and accidentally giving them a master key to every door in the building.
A sales manager, for example, should be able to open their customer accounts. But they have no business changing system-wide admin settings. RBAC makes sure the system enforces that line, even if someone tries to cross it.
Why It’s Critical
Logins get stolen. It happens—phishing, weak passwords, shoulder surfing in an airport lounge.
With RBAC, a stolen account is still limited to its assigned role. Without RBAC, that one breach could mean total system compromise.
It’s also a productivity thing. When people only see what they need, they’re not digging through irrelevant screens or tripping over options that don’t apply to them.
What to Test
- Can users log in and out cleanly, with sessions timing out when they should?
- Do navigation menus and UI elements change based on role?
- Does the backend check permissions for every API request, not just the frontend?
- If someone changes a URL to an “off-limits” page, does the system block them?
- Are role changes handled correctly—both upgrades and downgrades?
- Is every denied attempt logged, with enough detail to investigate later?
How to Test It Well
- Try the things you shouldn’t be allowed to do—this is negative testing in action.
- Automate role-based checks so permission bugs don’t sneak in during updates.
- Use a role/function matrix to make sure you’ve covered every possible combination.
- Test session management—what happens if you log in from multiple devices? If you leave a session open for hours?
Pro Tip: Testing what a role can do is easy. The real test is proving what it can’t do—because that’s exactly what an attacker will try.
Sample Test Case — RBAC for Sales Manager Role
| Field | Details |
| Title | Verify Sales Manager access to assigned customer accounts and restricted access to unassigned accounts |
| Objective | Ensure a Sales Manager can view/edit assigned accounts but cannot access admin functions or unassigned accounts. |
| Preconditions | - User with “Sales Manager” role exists - Admin panel restricted to Admin role - Backend RBAC logic implemented |
| Steps | 1. Log in with Sales Manager credentials. 2. Attempt to access /admin/users directly. 3. Attempt admin actions via API using JWT. 4. Check UI for hidden admin options. 5. Review audit logs for denied attempts. |
| Expected Results | - Direct admin access returns HTTP 403 Forbidden. - JWT scope does not permit admin functions. - Admin options hidden in UI. - Denied attempts logged (user, IP, timestamp). |
| Critical | |
| Tools | Postman, Browser DevTools, JWT.io, Burp Suite |
6. Integration Testing with Third-Party APIs
Enterprise software almost never works alone.
It’s plugged into payment gateways, CRMs, analytics tools, cloud storage, identity providers—you name it.
That’s its power. And its weakness.
Because here’s the catch: if even one of those connections breaks, entire business workflows can grind to a halt.
Why It’s Critical
A third-party API might be rock-solid on its own. But your integration can still fail—and often in ways you don’t expect:
- Data formats don’t match.
- Tokens expire unexpectedly.
- A vendor quietly changes an endpoint.
- Or the API just… slows down or disappears for an hour.
When that happens, the fallout is real: failed transactions, missing customer records, broken reports, angry users.
I’ve seen teams discover a payment API was failing only after customers started calling to ask why their orders were “pending” for two days. That’s not the moment you want to find out.
What to Test
- Data exchange accuracy – Is the data coming in and going out exactly what you expect?
- Performance under load – Can the API keep up during your busiest hours?
- Secure data transfer – No leaks, no weak encryption.
- Error handling – What happens if the API is slow, returns garbage data, or is offline?
- Fallback behavior – Does the system handle failures gracefully, and do users get clear messaging?
Techniques That Work
- Direct API Testing – Hit the real API and verify every response.
- Mocking/Simulation – Let you test without depending on live vendor uptime.
- Incremental Integration Testing – Validate each component before running end-to-end.
- Failure Injection – Simulate timeouts, bad payloads, or dropped connections.
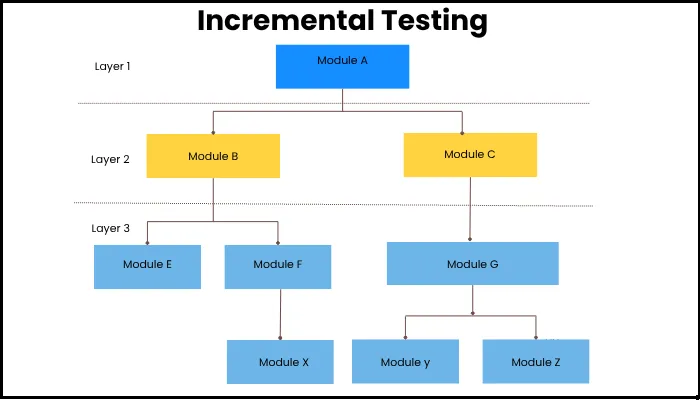
💡 Pro Tip: Pre-release testing catches problems before they ever hit production. Live monitoring catches them before customers notice. You need both.
Sample Test Case — Stripe Payment Intent API
| Field | Details |
| Title | Validate integration with Stripe Payment Intent API |
| Objective | Verify payments can be initiated, tracked, and handled correctly through Stripe’s API. |
| Preconditions | - Stripe sandbox keys configured - Network access to Stripe API - Valid Stripe test card ready |
| Steps | 1. Create a payment intent for $50. 2. Simulate a successful payment with a valid test card. 3. Capture the payment. 4. Fetch payment intent details from Stripe. 5. Simulate a failed payment with a declined card. 6. Verify order status updates in your system. |
| Expected Results | - Payment intent created with correct metadata. - Failed card returns the correct decline error. - Order status updates accurately. - Logs contain Stripe event IDs and request IDs. |
| Severity | Critical |
| Tools | Postman, Stripe CLI, WireMock, Splunk |
7. Audit Logging & Compliance Testing
In enterprise software, logs aren’t just a “developer thing.”
They’re proof.
Proof of who did what, when, and from where.
And in certain industries—finance, healthcare, government—that proof isn’t optional. It’s the difference between passing an audit and facing a fine that wipes out your quarter’s profits.
Why It’s Critical
Without reliable, complete logs, you’re blind.
If there’s a breach, you can’t investigate what really happened.
If a regulator asks for evidence, you have nothing credible to hand over.
If someone’s behaving suspiciously inside your system, you might never spot it until it’s too late.
And here’s the kicker—if your logs can be edited or deleted, they’re useless in court and a liability in an audit.
I’ve seen teams pull logs during a security incident only to realize the one crucial event wasn’t there. Not because it didn’t happen—because logging wasn’t done right. That’s a sinking feeling you don’t forget.
What to Test
- Every important action is logged — with timestamp, user ID, and source IP.
- Logs are immutable — nobody can quietly “clean up” history.
- Retention rules are met — whether it’s HIPAA, PCI-DSS, SOC 2, or internal policy.
- Details are deep enough for forensic analysis if something goes wrong.
How to Test It Well
- Log Injection Testing — Try sneaking fake entries into the logs; they should be blocked or flagged.
- Log Review & Analysis — Actually read them; check for completeness and consistent formatting.
- Alert Validation — Make sure important events trigger the right alerts in real time.
- Compliance Audit Simulation — Do a dry-run audit before the real one comes knocking.
Pro Tip: Logs that no one looks at are just expensive storage. The real value comes from reviewing and monitoring them, so issues get spotted while there’s still time to fix them.
Sample Test Case — User Account Modifications
| Field | Field |
| Title | Audit trail validation for user account modifications |
| Objective | Ensure all user account changes are logged with complete details and are tamper-proof. |
| Preconditions | - Audit logging enabled - User roles and access controls predefined - Test user with “HR Admin” role created |
| Steps | 1. Log in as HR Admin. 2. Modify another user’s contact info. 3. Change their role from “Viewer” to “Editor”. 4. Delete a user profile. 5. Access audit logs and verify entries. 6. Attempt to modify a log entry via CLI or DB. 7. Confirm system blocks the change and logs the attempt. |
| Expected Results | - Each action logged with timestamp, user ID, action type, object affected, and source IP. - Logs are read-only. - Unauthorized log modification triggers an alert. - Logs downloadable in tamper-proof format. |
| Severity | High |
| Tools | Splunk, AWS CloudTrail, Elasticsearch |
8. Version Upgrade & Backward Compatibility
Updating enterprise software is like renovating a busy office—you need to keep everything running while making changes.
In large organizations, updates rarely roll out to everyone at once. Some teams get the latest version immediately; others may stay on the old one for weeks or months. If those versions can’t work together, data can break, workflows can fail, and operations can stall.
Why It’s Critical
Even small changes to data structures, APIs, or UI logic can silently break integrations.
Backward compatibility ensures older clients or modules still function after an upgrade.
Without this testing, failed rollbacks can cause extended downtime.
What to Test
- Data consistency across old and new version
- Ability to roll back without losing data or settings
- UI stability after updates
- API compatibility between versions
- Core workflows in mixed-version environments
Techniques to Use
- Regression Testing – Confirm existing features still work after updates
- Canary Releases – Deploy to a small group before full rollout
- Snapshot Testing – Detect unintended UI changes
- End-to-End Testing in Legacy Mode – Verify new versions integrate with older systems
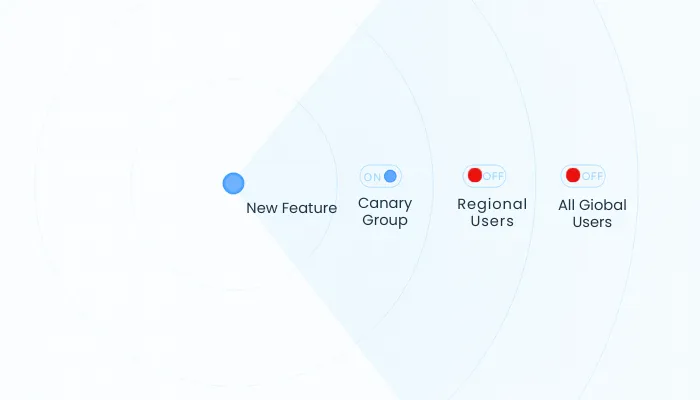
Pro Tip: Test both forward compatibility (old data in the new version) and backward compatibility (new data in the old version).
Sample Test Case — Data Integrity Post Upgrade
| Feilds | Details |
| Title | Validate data integrity after version upgrade and rollback |
| Objective | Ensure data remains accurate and accessible after upgrading to a new version and rolling back to the old one. |
| Preconditions | - App v5.0 running with populated database - Versioned API in place |
| Steps | 1. Insert sample transaction data in v5.0. 2. Upgrade to v6.0. 3. Retrieve data and verify accuracy. 4. Roll back to v5.0. 5. Confirm same data remains intact. 6. Add a new transaction in v5.0 and read it in v6.0. |
| Expected Results | - No data corruption or loss. - Business logic remains consistent. - Both versions handle data structures correctly. |
| Severity | Critical |
| Tools | Flyway, Postman, Jenkins, Selenium |
9. Business Logic Validation
Business logic is the brain of your software—the part that decides how things work, not just whether they work.
You can have a flawless UI and lightning-fast APIs, but if the logic underneath is wrong, you’ll get wrong results… just faster. And wrong results at scale mean revenue loss, compliance headaches, and customers who stop trusting you.
Why It’s Critical
When business logic fails, it’s not always loud or obvious.
A discount is applied when it shouldn’t be.
A tax rate is miscalculated for a certain region.
A compliance rule is skipped for a specific workflow.
The system still “works” technically, so functional tests pass. But in the real world? You’re bleeding money or breaking the law without realizing it.
What to Test
- Correct application of rules and workflows – Does the system always follow the company’s actual policies?
- Accurate data validation – Formats, values, and calculations should all match expectations.
- Transaction integrity – Even under odd scenarios, results should hold up.
- Rule-based variations – Pricing, tax rates, eligibility—all must adapt correctly to context.
- Edge cases – Boundary values and unusual inputs are often where the cracks show.
Techniques That Work
- Exploratory Testing – Go off-script to spot logic flaws test automation might miss.
- Decision Table Testing – Lay out inputs and outputs for multi-condition rules.
- Functional GUI Testing – Confirm the front-end applies the same rules as the back-end.
- Boundary Value Analysis – Push the limits with extreme inputs.
- Scenario-Based Testing – Use realistic, end-to-end workflows to validate behavior.
Pro Tip: Don’t design these tests in isolation. Sit with the product owners—they know the rules better than anyone, and they’ll catch gaps you won’t.
Sample Test Case — Tiered Discount & Tax Logic
| Field | Details |
| Title | Validate tiered discount and tax rules by U.S. state |
| Objective | Ensure bulk orders apply the correct discount tiers and state-specific taxes. |
| Preconditions | - User logged in with “Sales Ops” role - Regional tax settings configured for CA, TX, and NY |
| Steps | 1. Create a $25,000 sales order for a California client. 2. Apply tiered discount (e.g., 10%). 3. Verify state tax is calculated correctly. 4. Repeat for TX and NY clients. 5. Compare totals with business rules. |
| Expected Results | - Correct discount applied per business rules. - State taxes calculated accurately. - Invoice total matches expected calculation. |
| Severity | High |
| Tools | TestRail, Postman, Avalara API |
10. Disaster Recovery & Backup Restoration
Downtime isn’t a matter of if—it’s when.
It might be a sudden server crash. A corrupted database. Or a storm that knocks out your primary data center in seconds.
When it happens, there’s only one question that matters:
Not “Do we have backups?”
But “Can we restore quickly, lose as little data as possible, and keep the business running?”
Why It’s Critical
A real disaster can stop operations cold. Customers can’t log in. Orders can’t process. SLAs are breached. Trust starts to erode with every passing minute.
And here’s the hard truth—if you’ve never tested your recovery plan, your backups might just be useless files sitting in storage. Maybe they’re incomplete. Maybe they don’t restore cleanly. You won’t know until it’s too late.
What to Test
- Recovery Time Objective (RTO) – How fast can you be back online?
- Recovery Point Objective (RPO) – How much data can you afford to lose?
- Data integrity – Is the restored data actually correct and complete?
- Failover readiness – Can critical systems switch over instantly?
- Post-restore security – Are all reauthentication and access controls in place?
Techniques That Work
- Failure Scenario Simulation – Shut down key services or corrupt data to force a real recovery drill.
- Chaos Engineering – Inject failures randomly to uncover weaknesses.
- Full Interruption Testing – Pretend the whole system is gone and rebuild from backups alone.
Pro Tip: A recovery plan that’s never been tested is just a nice theory. Regular drills turn it into a guarantee.
Enterprise Software QA Metrics to Track
The point of testing comes down to one thing: make the software better.
But “we tested it” doesn’t mean much unless you can prove the testing is actually making a difference. That’s where metrics come in. The right ones will:
- Point to weak spots in your code or process.
- Show whether your testing is thorough enough.
- Reveal if bugs are getting fixed fast enough—or just piling up.
Here are the QA metrics that matter most for enterprise teams, and why.
- Defect Density Rate
- What it tells you: How many defects you’re finding per unit of code—a rough measure of code quality.
- Formula: Defect Density = Number of Defects Found ÷ Size of Software Unit
- Benchmark: Around 5–10 defects per thousand lines of code is common. Higher than that? You might have quality problems… or you’re missing tests entirely.
- Test Coverage
- What it tells you: How much of the codebase or feature set has been tested.
- Formula: Test Execution Coverage = (Executed Test Cases ÷ Planned Test Cases) × 100
- Goal: 80–90% coverage.
- Watch out: 100% coverage doesn’t mean “bug-free.” It just means every area got tested at least once.
- Percentage of Automated Tests
- What it tells you: How balanced your testing is between manual and automated work.
- Formula: Automation % = (Automated Test Cases ÷ Total Test Cases) × 100
- Why it matters: More automation means faster, more consistent regression testing—without burning out the QA team.
- Response Time
- What it tells you: How quickly the system answers back when a user (or another system) makes a request.
- Impact: If the system lags, productivity drops, tempers rise, and confidence in the platform erodes.
- User Capacity
- What it tells you: The maximum number of concurrent users the system can handle without choking.
- When it matters: Payroll runs, seasonal shopping spikes, or big product launches—basically, the moments you can least afford downtime.
- Mean Time Between Failures (MTBF)
- What it tells you: On average, how long the system runs before something breaks.
- Formula: MTBF = Total Operational Time ÷ Number of Failures
- Goal: The higher, the better. A low MTBF is a reliability red flag.
- API Response Times & Error Rates
- What it tells you:
- API Response Time: How fast API calls return data.
- API Error Rate: The percentage of calls that fail.
- Why it matters: In API-first architectures, slow or error-prone APIs don’t just annoy developers—they can stall entire business workflows.
- What it tells you:
- Functional Regression Defects
- What it tells you: How often updates break features that were working before.
- Impact: A high number means your deployments are risky and your users are frustrated—especially if the same things keep breaking.
Pro Tip: Don’t just take these numbers once and call it a day. Track them over time. Trends will tell you far more about the health of your QA process than a single snapshot ever could.
Conclusion
Every one of the 10 test cases we’ve walked through—whether it’s RBAC validation, load handling, or full-on disaster recovery drills—exists for one purpose: to make sure your enterprise software is reliable, secure, and ready for what’s next.
But here’s the thing—running these tests isn’t the finish line. The real win happens when you:
- Link QA results directly to business outcomes.
- Track your progress over time with the right metrics.
- Adapt your testing strategy as both the system and the business evolve.
That’s when QA stops being seen as “just a cost” and starts being recognized as a business driver—protecting revenue, safeguarding customer trust, and strengthening your brand.
Enterprise QA is never static. Integrations get deeper. User bases grow. Regulations shift. And the cost of failure keeps climbing. Your QA strategy has to scale with all of it.
Check out this case study how better QA helped Anyone Home cut issues by 25% and keep customers happy
That’s exactly what we do at ThinkSys.
Our QA experts design testing strategies that aren’t just thorough—they’re smart, scalable, and aligned to your business goals.
We help you:
- Identify the right critical test cases for your environment.
- Automate intelligently without sacrificing coverage.
- Build QA processes that prevent problems instead of chasing them.
Special Offer: Get a free 48-hour QA Gap Audit—limited to the next 5 sign-ups this quarter.
FAQS
Share This Article:



