The Complete Guide to Software Testing Services in 2026
Summarize With:

Harsh Goel
If you have been evaluating software testing services in 2026, you have probably already tried the obvious answers. More automation. A better platform. An extra QA hire. None of it really solves the issues.
The problem is not that you are testing too little. It is that AI-generated code volume has outpaced your QA architecture, and most of the fixes teams reach for are aimed at the wrong thing entirely.
In this guide, we will walk through what the 2026 testing services landscape actually looks like:
→The seven service models available right now
→The four failure patterns they are designed to solve
→And the one decision variable that changes the right answer for every regulated product.
How AI adoption is reshaping QA demands in 2026
A lot of CTOs who invested in AI code generation tools in 2024 expected delivery stability to improve. That is a reasonable expectation. If your engineers are writing code faster and with fewer errors, the quality of what ships should go up as well.
That is not what the data found. In 2024, Google's DORA team found that AI adoption across engineering organizations correlated with a 7.2% decrease in delivery stability. Not the increase anyone expected.
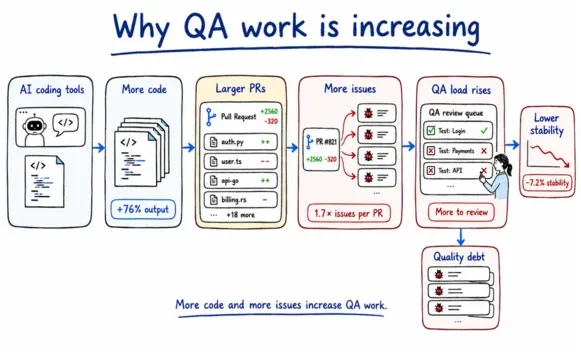
The root cause was not AI writing worse code. Only 39.2% of engineering teams actually distrust AI-generated code quality, according to that same DORA survey.
The root cause was batch size. AI makes writing code so frictionless that changesets grow larger. And DORA's decade of data consistently shows that larger batches introduce compounding defect risk regardless of how good the code itself is.
More AI development tools do not fix this. More AI adoption makes the problem worse.
The gap is pretty well quantified. A December 2025 analysis by CodeRabbit of 470 open-source pull requests found AI-generated code contained 1.7 times more flagged issues per PR than human-written code: 10.83 issues versus 6.45.
At the same time, Greptile's State of AI Coding 2025 found individual developer output up 76% per person: 7,839 lines per month versus 4,450.
Code volume and defect density are both scaling with AI adoption at the same time. If your QA capacity is not scaling proportionally, you are accumulating quality debt every single sprint.
"Over 40% of code written last year was generated by AI. However, we have far less data on how much of this code survived review and made it into production." — Kevin Thompson, CEO, Tricentis
The question is not whether you have enough tests. It is whether your QA architecture is built for the volume of code AI is now shipping. Figuring out where your team actually stands starts with knowing what your options are.
How ThinkSys baselines before recommending anything
We measure defect escape rate and mean-time-to-detection for the prior two quarters before touching any tooling or architecture conversation.
If MTDT exceeds 72 hours or the defect escape rate is above 3% per release, the QA model is not calibrated to the current code velocity. We then audit test-to-defect correlation: which tests are catching real bugs versus consuming CI time on stable code paths that have not changed in 18 months. That ratio, not coverage percentage, determines which service model your team actually needs.
What software testing services will include in 2026, and where the market has shifted
Most CTOs evaluating testing services in 2026 are basically choosing between two familiar options: outsourced manual testing or a better automation platform.
And that framing misses the real differentiator between providers, which is not which tools they use but whether they own test health or just execute test plans.
That distinction matters a lot more than it sounds. When you add QA headcount without changing architecture, you reproduce the same problems at a higher cost.
The whole point of changing your QA model is to change the structure of the problem, not just the number of people working on it.
Only 14.3% of organizations have reached optimized test automation maturity, according to PractiTest's 2026 State of Testing Report.
The other 85.7% are running automation that would benefit more from architecture work than volume increase. The seven service types in the current market, with honest accounting of what each one misses:
| Service Type | What It Catches | The Gap Most Teams Find Too Late |
| End-to-end QA ownership | Everything, if scoped correctly | None, if the partner has domain coverage |
| Managed test automation | Regression defects, coverage gaps, and flaky test elimination | Exploratory edge cases automation cannot anticipate |
| Exploratory testing retainer | Usability failures, workflow breakdowns, novel failure modes | Repeatability, regression coverage at scale |
| Regression optimization | CI pipeline speed, flaky test reduction, coverage efficiency | New feature coverage |
| Compliance/validation testing | Audit readiness, access control failures, risk analysis gaps | General functional quality |
| Performance and security testing | Scalability failures, security vulnerabilities | Functional correctness |
| Staff augmentation | Execution capacity | Architecture, ownership, or strategy |
That last row is the one most teams default to. Staff augmentation adds headcount under your direction. It does not change test architecture or maintenance ownership. If your QA is already broken, more people will reproduce the same problems at a higher cost. It is basically the same dysfunction, just more expensive.
The more urgent question is which failure pattern your current model is already living with. The service type you need depends entirely on which problem you are actually solving.
How ThinkSys maps the current state before recommending a model
We baseline the current test type distribution and what percentage of tests have a designated owner versus are effectively orphaned across product areas. If more than 40% of tests have no clear owner, the problem is a service model problem, not a coverage problem.
Staff augmentation will not fix it. We map test artifacts to product areas before any recommendation, so the service model is grounded in the actual gap, not the most visible symptom.
What commonly breaks down in in-house QA, and the pattern behind it
The companies in these cases did not fail because they did not care about quality. They had automation. They had processes. They were measuring things. They just were not measuring the right things, and by the time the real cost became visible, it was already embedded in the product. Each team thought they had a QA function. They had the artifacts of one.
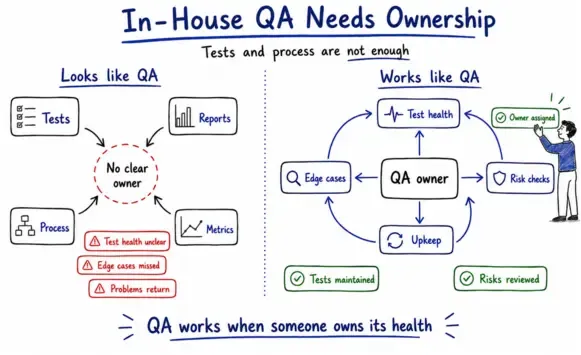
Automate everything mistake
For a fintech startup with 12 engineers, made a reasonable call: automate their regression suite. That is what teams do. But they did it without dedicated QA ownership, and over time, tests were written and abandoned. Regression consumed two full developer-days per release. Production incidents ran at three to four per month. The root cause was not insufficient automation. Nobody owned the test health. After implementing QA ownership and a maintenance cadence, production incidents dropped below one per month, and regression time fell to four hours automated plus two hours exploratory.
The developer-only testing blind spot
In 2023, Microsoft significantly reduced its QA engineering staff. It was a decision that made sense on the surface. Developers own quality through the whole development process, the argument goes, so why maintain a dedicated QA team? The decision generated a lot of industry debate, documented extensively across engineering forums and technology media. On Hacker News forum, some people wrote, "Maybe Getting Rid of Your QA Team Was Bad." Some people actually observed afterward was not great as they wrote: "Noticeably more bugs in updates since they dropped their QA team."
Developers test what they expect to work in the way they expect the user to use it. On the other hand, a good QA person is basically a personification of all the edge cases of your actual production users. An expert QA person knows how human users use the app better than the dev or product team.
Developers optimize for the happy path because that is how they reason about code. Adversarial thinking is finding how software breaks, not confirming how it works. That is a different cognitive frame entirely. Automation does not replicate it.
The AI-generated test debt
A mid-sized fintech running 120 microservices and 18,000 automated tests watched its CI pipeline balloon to four hours.
Two full-time senior engineers spent most of their working hours on test maintenance: updating broken selectors, correcting stale assertions, and debugging flaky AI-generated end-to-end tests.
Conservative cost: $140,000 to $180,000 in annual senior engineer salary consumed by preserving existing test artifacts rather than creating new coverage. After implementing test selection tooling and explicit ownership, pipeline time dropped from four hours to 45 minutes, and test maintenance effort fell 70%.
This pattern is not really anecdotal at this point. Flaky tests now affect 26% of engineering teams, up from 10% in 2022, a 160% increase across more than 10 million builds in three years.
A 2025 peer-reviewed study of GitHub repositories post-Copilot adoption found that experienced developers reviewed 6.5% more code after AI adoption, while their own original productivity dropped 19%. The authors described it as "a growing burden of maintenance on a shrinking pool of experts."
The healthcare compilance deficit
Warby Parker received a $1.5 million HIPAA civil money penalty from HHS OCR, enforced in December 2024. A 2018 credential stuffing attack exposed 197,986 individuals. The OCR investigation found three systematic violations: no risk analysis, no security controls validation, and no monitoring of system activity. Six years passed between the breach and enforcement. The testing gaps were embedded at the product level from the beginning. Solara Medical Supplies paid a $3 million HIPAA settlement in January 2025. A phishing attack exposed 114,007 patients' ePHI. Same structural failure: no risk analysis, no MFA validation, no email account monitoring.
The pattern across all four failures is identical. Each team was measuring test quantity while quality architecture silently degraded. But the right fix is not the same for each failure mode. Applying Mode 3 solutions to a Mode 1 problem is how teams spend $25,000 solving the wrong $500,000 problem.
How ThinkSys identifies which failure mode applies before recommending a fix
We baseline three numbers most teams do not track: flaky test ratio, test maintenance hours per sprint as a percentage of senior engineer time, and defect escape rate.
Maintenance burden above 15% of senior engineer time signals Mode 3. More than three production incidents per month despite automation signals Mode 1. No structured exploratory sessions in the sprint signal Mode 2. No documented compliance testing artifacts signal Mode 4. We categorize the failure mode explicitly before recommending any service type. The fix for Mode 1 is structurally different from Mode 3, and mismatching them is the most common, expensive mistake we see in initial engagements.
How companies are choosing between in-house, outsourced, and hybrid QA
The three variables that actually determine the right testing model for your team are not budget, team size, or tooling preference.
The first is regulatory exposure.
Are you handling ePHI, FDA-regulated data, or SOC 2 scope?
If yes, compliance testing is a mandatory architecture constraint, not an optional layer you can bolt on later.
The second is the velocity-to-maturity gap.
Are you releasing faster than your test suite can absorb new code without accumulating bloat and flakiness?
If yes, regression optimization and owned automation are your first priority. Not coverage expansion.
The third is the test maintenance burden.
What percentage of senior engineer time last sprint went to test maintenance rather than new coverage?
Above 15% means you have a test debt crisis, not a coverage gap. Adding more tests actually makes it worse.
| Situation | Recommended Model | Why |
| Under 50 engineers, non-regulated, early architecture | Managed automation partner for regression | No volume to justify QA headcount. You need a maintainable foundation before debt compounds. |
| 50 to 200 engineers, regulated industry | End-to-end QA ownership with compliance specialization | Regulatory exposure means generic automation creates legal risk, not just quality risk. |
| 200 to 500 engineers, accelerating release velocity | QA architecture partner plus embedded hybrid | Regression optimization and test debt elimination must precede any new coverage layer. |
Across all three situations, pure staff augmentation without QA ownership is the model that consistently reproduces the problem at a higher cost. It adds headcount without changing the architecture that created the gap in the first place. That is the whole issue with it.
Not sure which QA model fits your team? Talk to ThinkSys and get a clear view of what to fix first.
The talent market puts a concrete number on why internal hiring does not solve this as well. According to PractiTest's 2026 State of Testing Report (13th edition), QA professionals in optimized testing environments earn $57,167 on average, a 62% premium over peers in initial environments at $35,129. Hiring your way out of this problem means competing for engineers at that premium in a market with a real supply problem.
For most teams, those three variables produce a clear answer. For regulated products, one variable overrides the rest.
How ThinkSys runs the decision variables before any engagement.
We baseline the three decision variables above: regulatory scope, velocity-to-maturity gap measured by defect escape rate relative to release frequency, and maintenance burden as a percentage of senior engineer time. If the maintenance burden is above 15% and the release velocity is increasing quarter over quarter, we do not recommend adding new coverage first.
Architecture before volume, every time.
We model the true total QA cost before any recommendation: visible budget plus hidden engineering hours plus production incident cost. The recommendation is built on real economics, not the approved line item.
The observability vs. testing debate, where each approach actually fits
The case for observability over testing is actually not a new one. Netflix, Etsy, and Cloudflare have published compelling evidence that feature flags, canary deployments, and production observability catch failure modes that no pre-release test suite anticipates. Production conditions are fundamentally unreproducible in test environments.
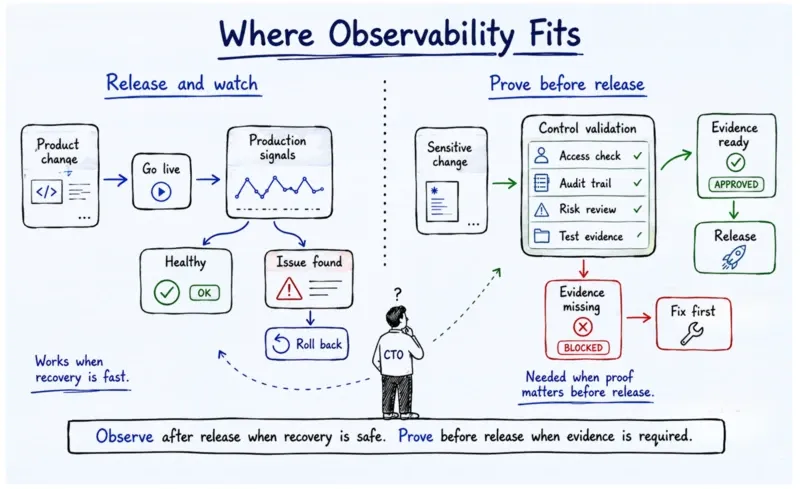
DORA's 2024 data shows elite performers deploying multiple times daily with change failure rates as low as 5%, achieved with less pre-release testing, not more. For consumer products with mature infrastructure and fast recovery capability, this argument has real data behind it.
But the argument has a hard boundary. And for a lot of teams reading this, that boundary is the one that actually matters.
You cannot canary-deploy a medication dosage calculation and observe whether patients are harmed. You cannot feature-flag a HIPAA-covered data pipeline and roll back after a breach.
Warby Parker did not get to roll back its $1.5 million penalty. Solara Medical Supplies did not get to roll back its $3 million settlement. Both enforcement actions followed the same structural failure: no risk analysis validation, no access control testing, no audit trail monitoring. These are compliance testing failures, not functional testing failures.
What HIPAA-compliant testing must produce is specific: documented risk analysis, access control validation evidence, audit trail monitoring protocol, and traceability from controls to test results. "We do security testing" is not a compliance artifact.
Kneat's 2024 State of Validation Report found that retrofitting compliance validation after an incident costs three to five times more than building it in from inception. 61% of regulated-industry professionals reported increased validation workload that year.
The FDA's Computer Software Assurance framework, which replaces traditional Computer Software Validation for cloud and SaaS products in regulated spaces, establishes the same standard: documented evidence of controls validation built from project inception, not assembled before an audit.
The required artifacts are risk analysis documentation, design specifications, test protocols, and traceability matrices. Functional test results alone do not satisfy them. The framework is explicit about that, and enforcement outcomes reflect it.
With the model identified and the compliance constraint established, the remaining risk is in evaluation. The question is whether the partner you are considering can actually deliver the architecture, or will deliver headcount under a different label.
How ThinkSys maps compliance scope before touching test architecture
We analyze current compliance testing artifacts before anything else: documented risk analysis, access control validation evidence, and audit trail monitoring protocol. Most teams discover they have functional testing documentation, not controls validation documentation. These are not the same thing. The distinction between "we tested security" and "here is the documented evidence of our controls validation" is the difference between $0 and $1.5 million in OCR exposure. For regulated-industry clients, we establish compliance testing scope as a first-order constraint on the entire QA architecture, not a layer added on top of functional testing after the fact.
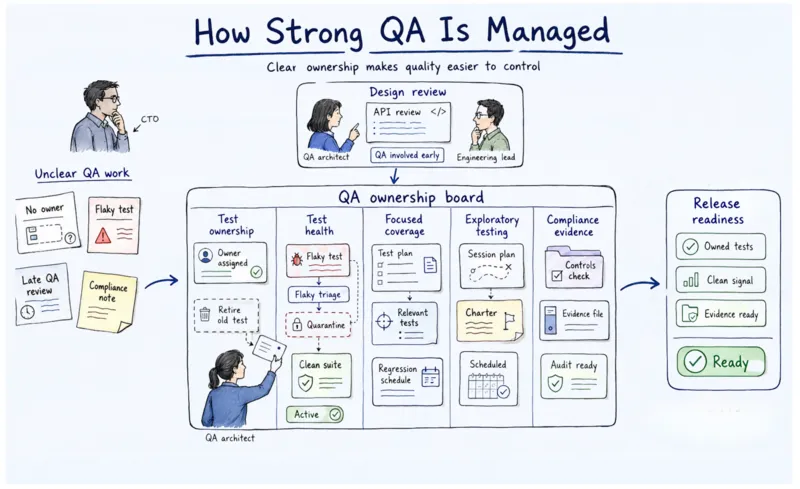
Six questions that separate QA architects from headcount vendors
Most vendor evaluations fail before the first question gets asked. They open with "What tools do you use?" And that is kind of the wrong frame. Playwright now sits at 45.1% adoption among QA professionals, with Selenium declining to 22.1%. Tool access is basically a commodity at this point. The questions that actually differentiate providers are about judgment: specifically, whether a provider has ever had to kill tests, not just write them.
- Show me a regression suite you have optimized, not built. What percentage of tests did you cut, and how did you measure the coverage impact?
Cutting tests requires architectural judgment. A provider who has only built suites cannot really answer this. If they respond with tests written rather than tests eliminated, they have not solved the maintenance problem. - What is your test ownership model when the product changes rapidly?
The right answer describes explicit ownership by product area, scheduled maintenance reviews, and flaky test triage protocols with SLAs. The wrong answer describes reactive fixes when tests start failing. - What is your flaky test rate target, and how do you enforce it?
According to TestDino's 2026 Flaky Test Benchmark Report, the functional threshold for CI pipeline confidence is below 2%. Above that rate, your suite loses the signal-to-noise ratio you need for deployment decisions. Any provider who does not know this number is not managing it. Follow up: What happens to a test that exceeds three flaky failures in 30 days? - How do you structure exploratory testing in order to cover what automation cannot anticipate?
The right answer: session-based, charter-driven, scheduled as a first-class budget item, integrated with automation feedback loops. Automation-only providers will not have a substantive answer here. - What does your compliance testing produce as documented evidence for our regulatory context?
For regulated industries, the answer must describe risk analysis validation artifacts, access control testing documentation, and audit trail evidence. "We do security testing" is not the answer. - What does your QA architecture look like at month 12 versus month 1, as our release velocity doubles?
The right answer: test selection strategy, regression pyramid optimization, and explicit plans for what gets automated, explored, and retired. Providers who describe adding more tests without describing test retirement have not solved the maintenance problem.
These questions change the frame of the decision. Not "what does QA services cost?" but "what is QA dysfunction already costing your team, and what does the destination look like?" That is the calculation most teams have never actually run.
How ThinkSys answers these questions before a client conversation
We apply these six questions to our own past work before any engagement. If we cannot demonstrate the answer with specifics from comparable engagements, measurable outcomes, not general claims, we do not claim the capability. We provide engagement documentation from client profiles comparable to the prospect: same industry, same team size, same regulatory context. The evaluation is calibrated against a real reference, not a generic case study deck.
What good QA architecture looks like in practice, and what it actually costs
Every engineering team at this stage is already paying for QA. The question is not whether to spend. It is whether you are spending $25,000 to $100,000 per year on QA architecture from specialists, or $500,000 to $1 million per year on the consequences of not having it: developer time drain, flaky pipeline reruns, production incidents, customer churn, and the occasional lost enterprise deal.
Bug0's 2026 Quality Tax analysis found a 45-engineer team at $10 million ARR losing $540,000 annually in developer time drain from QA deficiencies. That is 30% of the engineering payroll. The whole true QA cost, including hidden engineering hours, ran six times what appeared on the P&L: $750,000 to $1 million against a visible budget of $140,000 to $180,000.
The supply side compounds it as well. According to PractiTest's 2026 State of Testing Report (13th edition), the engineers capable of solving this architecturally earn $57,167 on average, a 62% salary premium over peers in initial-maturity organizations at $35,129. Experienced QA partners amortize that expertise across dozens of engagements. Internal hiring cannot replicate the economics.
Here is what a well-architected QA function looks like for a 50 to 500-engineer SaaS company in 2026.
If you are going to fix this yourself, start with three questions using data from your last sprint.
- What percentage of senior engineer time went to test maintenance rather than new coverage?
If the answer is above 15%, run the test-to-defect correlation audit now. Map which tests caught real bugs in the last two quarters versus which ones consumed CI time on code paths that have not changed. Cut before you add. That single audit will tell you more about your QA architecture than any coverage percentage report. - What is your current flaky test rate, and does anyone own the triage?
If no one owns it, set a 2% threshold this sprint. Any test exceeding three failures in 30 days gets quarantined immediately, regardless of what it nominally covers. The signal loss from a noisy suite is worse than the temporary coverage gap. - If a compliance auditor asked for documented evidence of controls validation tomorrow, could you produce it?
Pull your last security test run and check whether it includes documented risk analysis, access control validation evidence, and audit trail monitoring protocol. Functional test results and controls validation documentation are not the same artifact. If yours are the former, you have compliance exposure that predates your next audit by months.
If the answers expose structural gaps rather than execution gaps, what you really need is pattern recognition that comes from having rebuilt this before. A QA architect who has rebuilt this at a dozen companies knows which 30% of an 18,000-test suite to cut first. They have seen what the 2023 Microsoft QA reduction cost in shipped regressions. They can look at your defect escape rate and name the failure mode before a production incident names it for you. That pattern recognition does not exist in a new hire's first six months. It comes from cross-system experience with failure modes your team has not yet encountered.
At ThinkSys, that is the work we do: rebuilding QA architecture for SaaS companies at the exact stage where the current model stops working.
Warby Parker's $1.5 million penalty arrived six years after the breach that triggered it. The testing gaps that created that exposure were embedded at the product level from the beginning. The cost of catching them early was a fraction of the enforcement action. That gap between early investment and late consequence is the only variable still in your control.
How ThinkSys structures the first 30 days
We see the full true QA cost picture before recommending any architecture change: visible budget plus developer hours on maintenance, pipeline waste from flaky reruns, production incident cost, and compliance gap exposure mapped to documented testing gaps. If the total QA cost, including hidden engineering hours, is more than three times the visible QA budget, the ROI case is already in the data. We deliver the internal cost model as the first engagement artifact: defect escape rate against release frequency, maintenance burden as a percentage of senior engineer time, pipeline waste from flaky reruns, and compliance exposure mapped to documented testing gaps.
Want to know what your QA gaps are costing you? Share your setup with ThinkSys, and we will help you plan the next step.