Regression Testing Strategies for Complex Enterprise Systems
Imagine this: It’s the beginning of a new fiscal quarter for a US-based manufacturing company. Their enterprise resource planning (ERP) system processes thousands of orders every day and integrates with inventory, billing, and supplier systems. Much like any other software, the development team pushes a new update to introduce a feature that tweaks the way invoice due dates are calculated.

Everything looks fine in the code review, and the feature passes its tests. However, two weeks later, during the end-of-quarter closing, the finance team discovers that several invoices are mismatched, leading to a delay in supplier payments.
The cause of this issue? A minor invoice due date change unexpectedly interacted with custom workflows and historical data.
Scenarios like this are far from rare. According to a study by the Consortium for Information & Software Quality (CISQ), the cost of poor software quality in the U.S. (including failures, technical debt, vulnerabilities, and other related expenses) reached $2.41 trillion in 2022.
Given the high stakes, enterprises cannot afford to overlook anything that threatens stability.
With that in mind, regression testing becomes essential. As enterprise software is heavily integrated and customized, even small changes carry a considerable risk of unintended side effects. Having well-designed enterprise regression testing strategies is what separates organizations that can deliver reliable updates from those that suffer from product incidents and failures.
In this article, you’ll gain information on the most effective regression testing strategies for enterprise systems, along with the right tools and metrics for success.
Why Do You Need a Different Approach for Enterprise Systems?
Enterprise software is entirely different from a small app or a consumer-facing product due to several interconnected systems where a single code change can send waves across various modules. With unique requirements, running traditional regression methods isn’t going to get the job done effectively, and the following reasons back up this claim:
- Multiple Dependencies: As stated above, enterprise systems comprise numerous modules and integrations designed to cater to the diverse needs of an enterprise's various departments.
What may seem like a minor update in a component, such as a new payroll tax calculation in an HR platform, can trigger unexpected failures in reporting dashboards, approval workflows, or external APIs.
A generic regression plan that doesn’t account for these cross-application dependencies risks leaving critical gaps in test coverage. - High Volume of Configurations and User Roles: Unlike consumer apps with limited user types, enterprise systems serve diverse roles and regions, each with custom permissions and workflows.
A single update might affect only a subset of roles, making it impossible to rely on one-size-fits-all regression suites. - Cost of Failure: The cost of downtime or defects in enterprise environments is exponentially higher than in smaller systems. Regression testing for enterprise software must be strategic and preventative, focusing on both technical quality and business impact, saving companies millions of dollars every year.
Must Read: Effective guide to enteprise software testing
How does Regression Differ from Retesting?
A common source of confusion in software quality assurance is the interchangeable use of the terms regression testing and retesting. While both are critical for ensuring software quality, they serve distinct purposes and are complementary processes within the software development lifecycle.
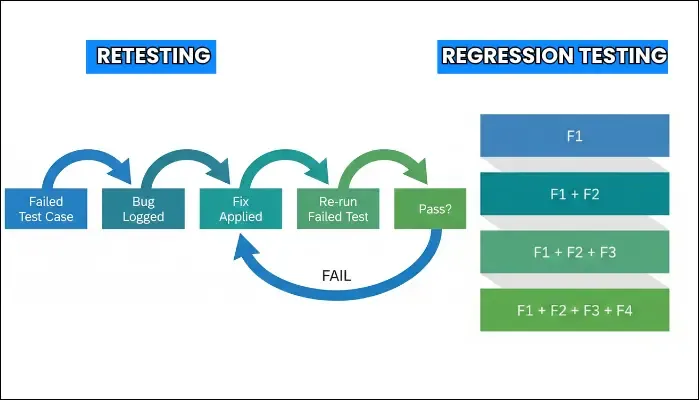
- Retesting: Performing retesting involves verifying that a specific defect has been fixed. Upon identifying a bug, the developer provides a fix, and the tester will re-execute the previously failed test case to confirm that the issue no longer exists and the software behaves as expected.
The scope of retesting is narrow, as it is concerned only with the area where the defect was found originally. - Regression Testing: On the contrary, regression testing has a broader objective. By performing regression testing, you ensure that new code changes have not adversely affected previously working functionality. The scope is expansive, often covering major functionalities or a significant portion of the app.
Retesting and regression testing work in a symbiotic sequence. After a developer provides a bug fix, retesting is performed first to confirm the fix’s efficacy.
Once the retest passes, regression testing is conducted as a final safeguard to ensure that the fix itself did not introduce any new issues. The dual-stage verification process guarantees both the resolution of a specific problem and the ongoing stability of the system.
Top Enterprise Regression Testing Strategies
Taking random decisions isn’t going to sustain your enterprise software in the long run, especially when it comes to regression testing. Given the scale, interdependence, and critical nature of enterprise software components, a haphazard approach to regression can be time-consuming, resource-intensive, and ineffective.
With that in mind, the following are the top regression testing strategies for complex enterprise systems that you can follow to ensure that your enterprise software remains stable and functional after every update.

- Risk-Based Regression: Enterprise environments have legions of test cases, making it impossible to run every single one of them with every release. One of the most important and effective enterprise regression testing strategies is to employ risk-based regression testing.
As you cannot run every test, you need to prioritize test cases based on risk and criticality. And for that, you need to run an impact analysis that helps you understand the changes made to the application and identify all potentially affected areas and their dependencies.
You need to take a systematic approach towards risk-based regression, where you need to:- Identify Risk: Evaluate the application’s critical features and functionalities to identify the areas at risk.
- Calculate the Impact: The next thing you need to do is calculate the probability of failure and what the accompanying damages could be.
Prioritize Test Cases: Once you calculate the business impact of each test case, you can rank them based on the highest-risk area, which should be listed earlier.
Implementing this structured approach ensures that resources are allocated where they matter most, allowing the desired team to identify bugs more efficiently. The following risk-based prioritization matrix can help you understand it better:
Probability of Failure Impact (on Business/Users) Test Priority High (frequent changes, complex code) High (revenue loss, major disruption) Immediate High (frequent changes, complex code) Low (minor inconvenience) Medium Low (stable code) High (revenue loss, major disruption) High Low (stable code) Low (minor inconvenience) Low
- Selective Regression: Sometimes, you don’t want to run every test due to resource or time limitations. Or, in some cases, running every test case isn’t practical. In such scenarios, you can leverage the selective regression testing approach, where you only test parts of the system likely to be affected by recent changes.
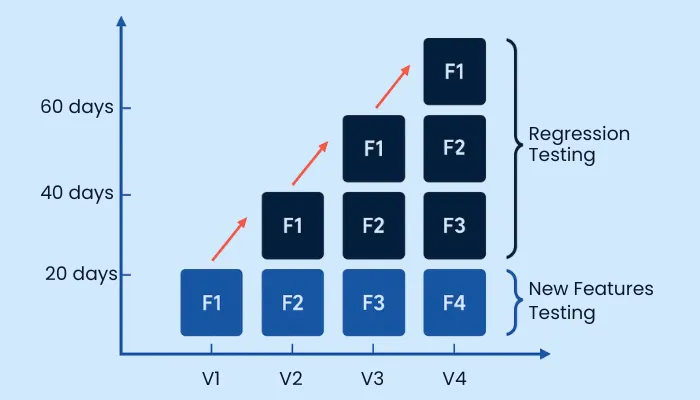
By testing only parts of the existing regression test suite, you not only test all the critical areas likely to be affected by changes, but also save the company’s testing cost and efforts.
Usage of selective regression testing for enterprise software is not just about saving money. Implementing this strategy has been proven to be beneficial when there are small to medium impact changes in the software or between development cycles for new features.
The following techniques can help you in performing selective regression testing:- Dependency Mapping: As enterprise software comprises various components and dependencies, dependency mapping helps in identifying and visualizing the interconnected components to understand the radius of a change by showing which components rely on an updated part.
- Version Control History and Traceability: The version control history tracks changes to the code. Traceability Matrices link requirements to code and tests. When you combine these tools, you allow testers to efficiently identify the exact subset of test cases that cover the modified files or features, ensuring a minimal yet necessary regression run.
- Striking the Balance between Manual and Automation: One of the biggest miscalculations people make in regression testing is regarding manual and automated testing. There is no denying the fact that automation is central to modern QA strategy, but it's not a silver bullet. While some organizations rely too heavily on automation, others may not do it enough.
The most effective approach is a hybrid one that strategically balances both testing efforts to achieve maximum coverage and ROI.- Automation is best suited for repetitive, high-volume, and high-risk tests that are part of a stable and predictable part of the app. It offers the speed and consistency necessary for continuous testing in CI/CD pipelines.
- Manual testing is best suited for exploratory testing that requires human intuition and adaptability to detect software issues. Furthermore, it is ideal for testing new features and complex scenarios that require subjective evaluation.
Although many teams attempt to automate as needed, the danger lies in over-automation, which can lead to bloated suites and excessive maintenance overhead. Automating more than necessary can also lead to a negative ROI and a rise in test debt.
A credible and effective strategy involves automating test cases based on their frequency, stability, and likelihood of errors.
- Aim for Repeatability: One of the key characteristics of regression testing is performing the exact same tests over and over again, which requires process repeatability. When you don’t have a repeatable testing process, you tend to get inconsistent results even after performing the same tests multiple times.
Your goal is to conduct multiple regression tests of the same function while ensuring that they are the same. Even though there will be some changes when working on the new version, you have to ensure that you keep the consistency in check while performing regression testing on your enterprise software. - Creating a Reusable Test Data Source: Regression testing is only as effective as the data it runs on. Without a restorable data source, test results can vary from cycle to cycle, making it complex to identify whether a failure is due to a code change or inconsistent test conditions. Considering that fact, the ability to restore and manage test data reliably becomes one of the most critical foundations of regression testing.
Unlike small applications, enterprise systems deal with massive, interdependent datasets that must remain accurate and consistent across repeated test runs.
To achieve this, your QA teams need a controlled mechanism to create, refresh, and roll back test data to a known state before every regression cycle.
Key Steps to Implement a Restorable Test Data Process:-- Establish a Baseline: Begin by executing regression tests on the current system using a carefully prepared set of test data. These results serve as the baseline for all future comparisons, providing a reliable reference for identifying changes.
- Apply the System Changes: Now you need to introduce code updates, configuration changes, or new features to the enterprise software while ensuring the baseline dataset remains intact for comparison.
- Update Test Data for New Scenarios: Create or adjust test cases to reflect new functionality or modified workflows. For example, if a new payroll rule is introduced, the test dataset must include records that exercise the updated logic.
- Run Tests with Updated Data: Upon updating the test data, it's time to execute the regression suite again, this time using the updated data set, to verify that both new and existing functionalities behave as expected.
- Compare and Reset: Once you get the results, analyze them against the original baseline. Any unexpected discrepancies signal potential defects that need investigation. After successful validation, the new results become the baseline for the next cycle, ensuring an iterative and controlled process.
- Your App Should Be Automation Ready: The shift-left approach guides the teams to shift testing to the early stages of development. While that is surely effective for other testing types, it might not be effective while performing regression testing.
As stated earlier, regression requires repeatability for the test to produce any valid outcome. During the initial development stages, the software is not just unfinished; it's unstable and unpredictable.
Implementing automated regression testing earlier than it should can make the entire test case management process tedious and ineffective. Even though several actions influence the decision of the right time to perform regression testing, it all comes down to the flexibility available during development.
All you have to do is focus on identifying functions that are less likely to change and begin building regression tests around those areas first. - Effective Test Case Development: Creating test cases and designing effective test cases are entirely different things. While creating test cases is surely a major part, it’s the effectiveness that defines how useful these test cases will be.
Regression tests involve automating test cases, giving testers the notion that testing is done quickly. Undeniably, automation is quicker than running the same number of tests manually.
However, the real argument is, ‘Is every test case efficient and necessary?’ Moreover, you have to consider the time required for test case maintenance and evaluating failures.
Rather than chasing a high number of redundant test cases, the right approach is to enhance the efficacy of test cases. Using the right test case design techniques, such as equivalence partitioning and pairwise test design, you can revolutionize your test case design practice. - Regression-All Strategy: Once your enterprise application reaches a stable phase, you can implement a Regression-All testing strategy to strengthen quality assurance further.
Here, the testers will run the entire suite of regression tests, including all the previously validated features. Implementing this strategy is essential when a major release, patch, or configuration change is made to the application. Key benefits of this strategy involve:- Comprehensive coverage of every critical function.
- Risk mitigation for enterprise software.
- Increasing confidence in releases after a major upgrade.

Hurdles that Can Hinder the Success of Regression Testing Strategies
Every enterprise system is inherently complex, and this complexity tends to bring a unique set of challenges. The first step in tackling these challenges involves understanding them, and this section aims to provide you with all the information required to understand and eradicate them:
- Managing Extensive Test Suites: As an application evolves, its test suite grows in size and complexity, making it difficult to maintain and execute manually.
In this scenario, you need to have a proactive maintenance process to regularly review the test suite and eradicate outdated or redundant test cases that only consume time without providing any actual benefit. - Maintaining Test Data Integrity: The interrelated datasets of enterprise software should remain accurate across every test run for reliable results. If the data becomes outdated or inconsistent, tests may fail for reasons unrelated to code changes.
In that case, the best course of action is to utilize TestRail, Zephyr, or another test data management tool to refresh datasets and mask sensitive fields, thereby maintaining data integrity while meeting privacy requirements. - Flaky Tests: A test case may sometimes pass and sometimes fail even without any code changes. These test cases are known as flaky tests and pose a constant frustration for testers, as they create confusion and slow down release cycles.
Stabilizing test logic, improving synchronization, reducing dependencies on external systems, and regularly refactoring test cases are some of the practices that can minimize the possibility of flaky tests. - Ensuring Test Environment Consistency: Regression testing is only effective if the environment mirrors production. Yet, enterprise setups often involve multiple servers, APIs, and third-party integrations, where even small configuration changes can hamper test results.
You have to standardize environment setups and use automation to provision the same configuration every time to ensure consistency and make meaningful comparisons.
Optimizing your Existing Strategy
Several organizations are already performing regression testing, but their existing strategy requires some tweaks to provide the expected results. These key optimizations include:
- Build a Restorable Test Data Source: A reliable regression cycle depends on test data that can be recreated and reused across multiple runs. When there is inconsistent data, it becomes difficult for the tester to determine whether the failure was the outcome of a code change or due to shifting test conditions.
With that in mind, you need to set up a restorable data source through dedicated test management tools or automated database snapshots. Doing so will ensure that every run starts from a controlled state. - Implement a Maintenance Process: Over time, test suites naturally accumulate outdated or redundant cases that slow execution and increase maintenance effort. To eradicate this issue, you need to establish a regular review and cleanup process that helps remove obsolete tests, update expected results, and fine-tune automation scripts to keep the suite lean.
- Integrate with CI/CD Pipelines: Embedding regression tests into CI/CD pipelines ensures every code change is automatically validated before it reaches production.
This approach provides developers with immediate feedback, catches defects early, ensures stability across interconnected modules, and reduces the risk of regression failures. - Track KPIs and Metrics: Optimizing the existing process is incomplete without measuring its performance. You need to track top metrics and KPIs that reveal bottlenecks and demonstrate the value of your regression program to stakeholders.
KPIs and Metrics to Track
To effectively manage and optimize a QA program, it is essential to track the right metrics. These KPIs should bridge the gap between technical efforts and business outcomes, providing a clear picture of success for both QA engineers and executives.
- Defect Detection Rate: It is used to measure the effectiveness of your created test cases by tracking the number of bugs found in each risk area.
- Risk Coverage: Here, you will monitor the completion of tests in high-risk areas, ensuring that the most critical functionalities are validated consistently.
- Time-to-Release Cycle: By tracking the time it takes for a feature to move from development to release, you can directly measure the impact of your QA program on overall business velocity.
- Resource Utilization: Here, you need to track both automation execution time and manual testing efforts to identify bottlenecks and justify ongoing investments in tools and personnel.
The Modern Toolkit for Enterprise-Scale Regression Testing
Selecting the right tools makes all the difference while performing regression testing. Gaining knowledge about tools isn’t limited to determining which tool to pick, but also involves the types, advantages, and limitations.
With that in mind, this section categorizes automated regression testing tools into four categories so that you can make an informed decision.
- Open-Source Frameworks: The first category is open-source frameworks that include Selenium and Appium. Selenium is the industry standard, offering unparalleled flexibility, broad support for programming languages, and an extensive community.
However, it comes with a steep learning curve and requires significant coding expertise, making it unsuitable for non-technical teams. Additionally, it’s highly susceptible to the maintenance tax resulting from UI changes. - All-in-One Platforms: The next is a comprehensive All-in-One Platforms that provide a complete toolkit for web, mobile, API, and desktop testing. Katalon Studio and TestComplete are the top names leading this category and offer built-in features, integrations, and a more structured environment than open-source frameworks, making such tools accessible to a wider range of testers.
While they simplify many aspects of testing, they may not offer the same level of flexibility as open-source solutions for customized enterprise systems. - Low-Code/No-Code Platforms: Not just quicker but feasible as well. The low-code/no-code platforms allow business analysts, manual testers, or any other non-technical user to create and maintain automated tests without writing a single line of code.
Using Leapwork, BugBug, or Testim, you can significantly accelerate the time to value and broaden the engagement with the testing process. - AI-Native Platforms: With Platforms such as VirtuoseQA leading the way, AI-native testing is the most advanced and disruptive category here. These tools utilize AI and machine learning to address the single biggest problem of previous generations: maintenance overhead. AI-native platforms offer self-healing tests that automatically adapt to UI changes, natural language test creation, and AI-driven insights. Furthermore, they provide a transformational ROI by freeing QA teams from mundane maintenance, allowing them to focus on strategy coverage.
Conclusion
With the continuous evolution of enterprise systems, regression testing is transitioning from a safety net to a strategic action for business continuity. With the rise of AI-driven testing and deeper integration into CI/CD pipelines, the future of regression testing will be faster and more aligned with business outcomes.
For organizations managing enterprise software, the complexity of regression testing is only going to increase. And, keeping pace requires not just automation, but a specialized approach tailored to your enterprise-level dependencies.
You need the right partner that can make all the difference in testing. And that partner can be ThinkSys. With over 12 years of QA experience, we’ve helped numerous companies design, implement, and optimize enterprise regression testing strategies that strike a balance between speed and reliability. Our expertise ensures that your systems remain stable even with rapid transformations.

FAQs
Share This Article:





