Microservices Testing Strategy: The 2026 Playbook for Faster, More Reliable Releases
Microservices testing strategy is no longer just a QA concern. In 2026, it directly affects release speed, production stability, engineering efficiency, and customer experience. Many teams struggle with microservices testing challenges, including flaky pipelines, slow feedback loops, and unreliable staging environments.
What Is a Microservices Testing Strategy?
A microservices testing strategy is a layered approach to validating distributed systems using unit, component, contract, integration, end-to-end, and production checks. Its goal is to catch defects early, protect service boundaries, reduce release risk, and maintain fast feedback in CI/CD.
As teams move from monolithic systems to independently deployed services, traditional testing models often start to break down. Long end-to-end suites, shared staging bottlenecks, and brittle integration checks create slow feedback loops that undermine the very agility microservices are meant to deliver.
Many teams still rely too heavily on broad E2E coverage to validate distributed systems. That approach may have worked better in monoliths, but in microservices it usually leads to slower pipelines, harder debugging, and lower release confidence. When one business flow crosses dozens of services, a failing E2E test rarely tells you where the real problem started. It only tells you something broke somewhere.
A modern microservices testing strategy must be layered, risk-based, and CI/CD-friendly. It should catch defects close to the change, enforce compatibility at service boundaries, validate critical runtime interactions, and reserve E2E tests for a small number of high-value user journeys.
In this guide, we explain how to build that strategy in practice. You will learn:
- why traditional testing models fail in distributed systems
- what to test at each layer
- where contract testing fits
- how to manage environments and test data
- how to structure CI/CD execution
- how observability, resiliency, and security testing strengthen release confidence
If your teams are dealing with flaky pipelines, staging conflicts, or slow release validation, this playbook will help you redesign testing around the realities of microservices.
Why Traditional Testing Strategies Fail in Microservices Architectures
Traditional testing strategies were designed for systems with tighter boundaries, fewer deployments, and more centralized ownership. Microservices change all three. Services are developed and released independently, communication often happens across APIs and events, and failures can spread in ways that are hard to predict from a single test flow.
That is why testing practices that feel acceptable in a monolith often become expensive and unreliable in microservices.
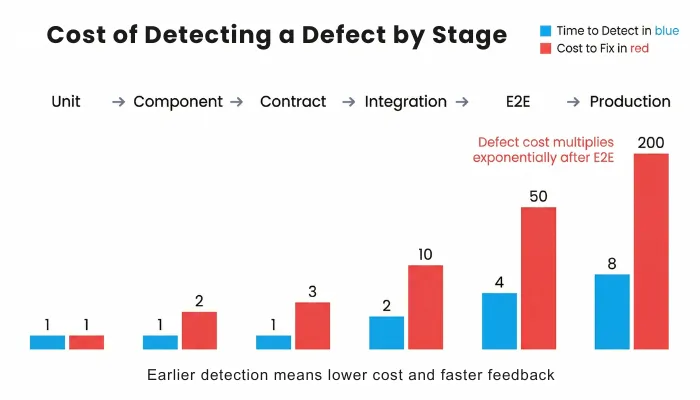
- Distributed failures are harder to detect: In a microservices architecture, one degraded service can trigger failures in multiple downstream services. A timeout in one dependency can become a retry storm in another. These issues rarely appear clearly in broad user-flow tests, which makes root cause analysis slower and more expensive.
- Asynchronous systems reduce determinism: Many microservices rely on queues, brokers, and event-driven processing. In these systems, success is not always tied to a single request-response cycle. Events may arrive later, out of order, or after retries. That makes traditional assertions less reliable unless tests are designed for eventual consistency.
- E2E-heavy strategies slow down delivery: When release confidence depends mainly on long end-to-end suites, feedback arrives too late. By the time a failure appears, the code has already moved through multiple stages, the context is weaker, and several teams may be involved. That slows diagnosis and encourages teams to treat test failures as noise instead of useful signals.
- Too much E2E recreates a distributed monolith: Over-relying on E2E testing forces services and teams to move in lockstep. Pipelines become brittle. Debugging becomes cross-team work. Autonomy decreases. In effect, the architecture is distributed, but the delivery model starts behaving like a monolith again.
The core lesson is simple: microservices need a layered testing strategy because no single test type can provide enough confidence on its own.
Building a Microservices Testing Portfolio: A Layered Approach to Risk-Based Quality
With several integrations and components, you cannot validate a microservices architecture through a single test layer. For effective testing and maximum coverage, you need a blend of test types, each designed to control a specific class of risk. The mistake many teams make is treating these layers as a maturity ladder rather than as simultaneously necessary safeguards.
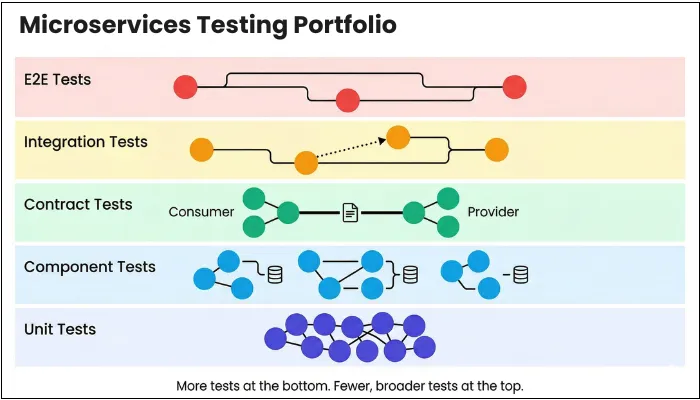
Microservices demand layered testing as no single level can provide sufficient confidence on its own.
This layered model defines a practical microservices testing approach aligned with real-world delivery risks. The goal of having a detailed portfolio is risk-weighted confidence, where you place more tests where failures are cheaper to detect and fewer tests where failures are expensive to diagnose.
Common Microservices Testing Mistakes That Slow Down Delivery
Even when teams understand the need for layered testing, they often make a few recurring mistakes that weaken release confidence and slow delivery.
- Relying too heavily on E2E tests: End-to-end tests are important, but they should validate only a small number of critical user journeys. When teams use E2E tests as the main safety net, feedback slows down and failures become harder to diagnose.
- Skipping contract validation: Without contract testing, breaking interface changes often surface too late in integration or staging. That creates avoidable cross-team friction and increases deployment risk.
- Overusing shared staging: Shared staging may work for smaller systems, but in larger microservices environments it often becomes a bottleneck. Contention, drift, and unstable state make failures difficult to trust.
- Using uncontrolled test data: Unstable or production-like data without proper control introduces noise into the test suite. Teams then spend more time debugging the data than validating the software.
- Treating observability as an operations-only concern: In microservices, observability is not just for production support. Logs, traces, and metrics are essential for understanding why integration and E2E tests fail.
- Running every test on every pull request: Not every test belongs in the PR gate. Running all tests on every change slows feedback, increases pipeline noise, and encourages teams to ignore failures instead of acting on them.
The goal is not to test more. The goal is to place the right checks at the right layer and run them at the right stage of delivery.
For teams asking how to test microservices effectively, the answer starts with assigning the right checks to the right layer.
What to Test at Each Layer in a Microservices Architecture
When it comes to building an effective microservices testing strategy, it all depends on testing the right layer at the right time. Each test level exists to reduce a specific interaction risk, especially where services communicate with each other. The following table includes the test types and what you need to test at each layer.
This includes defining clear roles for integration testing in microservices and limiting end-to-end testing in microservices to critical business flows.
Test Level
| Primary Goal | What to Test | What Not to Test | Microservices Interaction Risk Addressed | Typical Tools and Approaches |
| Unit | The goal is to ensure that a service's internal logic behaves correctly in isolation. | Test business rules, validation logic, edge cases, and error handling that are fully contained within the service. | Avoid testing databases, network calls, message brokers, or interactions with other services. | It reduces the risk of internal defects propagating to downstream services during integration. | Commonly implemented using JUnit, TestNG, pytest, Jest, or other xUnit-style frameworks. |
| Component / Service | Validating a service as a deployable unit in conditions close to production. | Include service APIs, database schema and migrations, configuration, adapters, and retry or timeout behavior in testing. | Do not include real downstream services or full end-to-end workflows at this level. | This layer catches service-level failures before they manifest as cross-service outages. | Often implemented using Spring Boot Test, Testcontainers, WireMock, and container-based test setups. |
| Contract | Your motive is to guarantee compatibility between independent consumer and provider services. | Test API schemas, request and response structures, event payload formats, and backward compatibility rules. | Business logic and user interface flows should not be tested here. | With this approach, you prevent breaking changes between services without requiring coordinated deployments. | Common tools include Pact, Spring Cloud Contract, and OpenAPI schema validation utilities. |
| Integration | The goal is to verify correct runtime behavior between a small number of real services. | Verify that authentication, authorization, serialization, network behavior, and asynchronous message exchange occur between two or three services. | Avoid validating complete user journeys or the entire system at once. | This level uncovers interaction failures that cannot be detected by unit or contract tests alone. | Docker Compose, Kubernetes test namespaces, and REST or messaging clients are the top tools for this testing. |
| End-to-End (E2E) | You aim to confirm that critical business flows work correctly from a user perspective. | Test a limited set of core journeys, such as onboarding, checkout, or payment confirmation. | Avoid exhaustive edge cases, deep service logic validation, or non-critical paths. | This layer ensures that essential user flows are wired correctly across the platform. | Commonly implemented using Playwright, Cypress, or Selenium. |
| Production Checks | The goal is to validate system behavior under real production traffic and conditions. | Synthetic transactions, health checks, canary deployments, and service-level objective compliance are all part of this testing. | Detailed functional validation and exploratory testing should not be performed at this stage. | This layer detects failures that only appear under real traffic, data, and load patterns. | Synthetic monitoring, canary releases, and observability platforms are used for implementing this testing. |
Contract Testing in Microservices: Ensuring Safe and Independent Deployments
At the core of a microservices architecture is communication between services. These services have dedicated contracts that specify expected requests and responses. Contract testing is about validating contracts and the interactions between services in a microservice architecture. The service receiving the request is the provider, whereas the service making the request is the consumer. Contract testing evaluates the behavior of both services to ensure seamless communication between them.
Effective contract testing can deliver several benefits:
- Better cross-team collaboration.
- Enhanced reliability and system stability.
- Faster development cycles
- Minimal service disruptions and integration issues.
Types of Contract Testing: Consumer-Driven vs Provider-Driven
Contract testing is of two types: consumer-driven and provider-driven.
- Consumer-Driven Contract Testing: The consumer is the one making the request and is the primary focus in this contract testing type. In this approach, the consumer defines a contract with requirements from the provider. The provider then uses these contracts to verify that its responses meet the consumer’s expectations. Consumer-driven contracts work especially well when teams deploy independently and when providers serve multiple downstream services.
- Provider-Driven Contract Testing: Provider-driven contract testing starts from the provider’s perspective. Here, the provider defines a contract that represents what it guarantees to all consumers. Consumers validate their implementations against this contract to ensure compatibility. PDCT is commonly used when a service is highly stable, widely shared, or externally exposed, such as a public API or a core platform service.
Where Contract Testing Fits in the Microservices Testing Pyramid
Component tests confirm that a service works correctly in isolation. Contract tests then verify that the service communicates correctly with other services at the interface level. Integration tests then validate runtime behavior across a small number of real services.
This workflow is important because contract testing reduces the need to rely on broad integration or end-to-end tests to catch breaking changes. When contracts are enforced consistently, integration tests become narrower, and E2E tests can be reserved for a small number of business-critical journeys. In practical terms, contract testing absorbs most of the change risk in microservices, while integration tests absorb runtime risks, and E2E tests absorb system-wiring risks.
Example Workflow for Contract Testing in CI/CD Pipelines
A typical workflow starts with the consumer defining or updating a contract based on their needs. The contract is committed to version control and published to a contract repository. The provider pipeline pulls all relevant consumer contracts and runs verification tests against the provider implementation. If all contracts pass, the provider is considered compatible and can be deployed independently. Integration tests then validate runtime behavior across selected services, and E2E tests confirm that core user journeys continue to function as expected.
Test Environment Strategy for Microservices: Staging vs Ephemeral Environments
As your system grows into dozens of independently deployed services, your environment strategy becomes part of your testing strategy. The staging environment is among the most popular methods, but it has one major problem: it's designed for monolithic architectures. So, when a single copy of the pre-production staging environment is pushed for testing, developers have to queue to deploy and test on the shared environment. All this goes against the flexibility that microservices intend to provide.
In microservices, environments must scale with parallel development and frequent deployments, or they become a hidden bottleneck. The staging environment provides some pros to the teams, including:
- A single, persistent environment allows multiple services to interact in a production-like topology, which helps surface basic integration issues.
- Minimal infrastructure automation is required, making this option relatively inexpensive to maintain initially.
- A shared space can be convenient for demonstrations, exploratory testing, and stakeholder reviews.
But, it's not just about the benefits, as the same environment has some limitations:
- Parallel deployments by multiple teams create contention, which makes it difficult to identify which change caused a failure.
- Over time, configuration drift emerges as hotfixes, feature flags, and partial rollbacks accumulate without a clean reset.
- Test stability degrades because system state changes between runs, even when the code under test remains unchanged.
- Feedback cycles lengthen as teams wait for the environment to stabilize before validating their changes.
When to Use Ephemeral or Preview Environments
Staging environments worked reasonably well for monoliths, but they become less effective as microservices systems grow. Ephemeral or preview environments are short-lived environments created specifically for a pull request or a change set. You get an isolated environment that exists only for the lifetime of that change.
With this model, you test your changes in isolation, reducing contention and eliminating long-term drift. As no other teams deploy into your environment, any failure you witness is directly attributable to your code, improving confidence and minimizing the feedback loop.
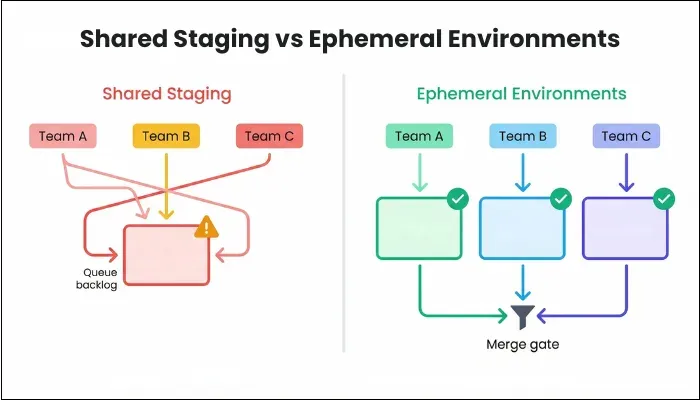
Environment Decision Matrix for Scaling Microservices Teams
| Factor | Shared staging is usually sufficient when | Ephemeral environments become necessary when |
| Team size | One or two small teams work on a limited codebase with tight coordination. | Multiple autonomous teams develop and deploy services independently. |
| Number of services | Fewer than ten services with low interaction complexity. | Dozens of services with frequent interface changes and dependencies. |
| Release frequency | Releases occur weekly or less frequently. | Deployments happen daily or multiple times per day. |
Test Data Management in Microservices: From Realistic to Deterministic Data
In microservices testing, unstable test data is one of the fastest ways to create flaky pipelines and slow debugging. Many teams assume that production-like data automatically improves confidence. In reality, uncontrolled data often creates inconsistent states, timing issues, and failures that are hard to reproduce.
Microservices need deterministic test data, not just realistic test data.
A test is useful only when it can be repeated with the same starting conditions and produce a reliable signal. If the data changes between runs, teams stop trusting failures because they cannot tell whether the issue is in the code, the environment, or the data itself.
A reliable microservices test data strategy usually includes the following:
- Seed known datasets at environment startup: Databases, queues, caches, and indexes should begin from a known and intentional state. Seed data should be versioned with code so changes are explicit, reviewable, and traceable.
- Align fixtures to service contracts: Test data should reflect the schemas, payloads, and expectations defined at service boundaries. When contracts change, fixtures should evolve with them. This helps surface incompatibilities earlier instead of letting them leak into integration or E2E stages.
- Isolate data per environment: One test run should never influence another. This is especially important in ephemeral or preview environments, where each pull request should have its own isolated state. Data isolation removes hidden dependencies and makes failures reproducible.
- Design for asynchronous behavior: In event-driven systems, tests should validate observable outcomes within expected time bounds rather than assume immediate consistency. Correlation IDs should connect the original trigger with downstream side effects so timing-related failures remain understandable.
- Treat flaky data as a system-level issue: If tests pass locally but fail in CI, fail once and pass on rerun, or depend on execution order, the problem is often not the test case itself. It is usually a signal that the data setup, teardown, or isolation strategy is weak.
Production-like data may make a system look realistic. Deterministic data makes it testable.
Designing a CI/CD Testing Strategy for Microservices
A microservices testing strategy creates value only when it fits the CI/CD pipeline. If every test runs on every pull request, pipelines become slow, noisy, and difficult to trust. If feedback arrives too late, teams batch changes, bypass gates, or start ignoring failures.
A better approach is to design the pipeline around risk, speed, and signal quality. Each stage should answer a clear question, and each test type should run where its signal is strongest.
Step 1: Pull Request Gate Focused on Fast Feedback
The PR gate should answer one question: Is this change safe to merge?
This stage should include fast, deterministic checks such as:
- unit tests for service logic and edge cases
- component or service tests with real local dependencies
- contract verification
- focused integration checks for critical service interactions
- a very small number of smoke checks where needed
Avoid broad E2E coverage here. The purpose of the PR gate is fast confidence, not full-system validation.
Step 2: Nightly Validation for Broader Interaction Coverage
Nightly validation should answer: Are wider service interactions still healthy?
This stage can include:
- broader integration coverage across selected service combinations
- asynchronous workflow validation
- limited E2E checks for important but non-release-blocking flows
- deeper non-functional checks where useful
Because this stage does not block individual merges, it supports deeper validation without slowing down daily development.
Step 3: Release Gate for Production Readiness
The release gate should answer: Is the platform ready for users?
This stage should validate:
- critical end-to-end user journeys
- performance smoke checks
- core security and compliance scans
- release-specific production readiness criteria
By the time code reaches this stage, most defects should already have been found earlier. The release gate should confirm readiness, not serve as the first place where quality is discovered.
What a healthy pipeline looks like
A healthy microservices pipeline is not the one with the most tests. It is the one that delivers:
- fast PR feedback
- explainable failures
- high signal-to-noise ratio
- limited release blockers
- confidence without slowing deployment
When structured correctly, the pipeline becomes a decision system, not a bottleneck.
Non-Functional Testing in Microservices: Performance, Resilience, and Security
Shipping feature-packed software is surely a great thing, but ensuring that it performs well in various conditions requires non-functional testing. Your software can return the right response and still fail under load, collapse when a dependency slows down, or expose security gaps at its boundaries. Non-functional testing is what determines whether your system survives real-world traffic and varying conditions.
Performance Testing in Distributed Microservices Systems
Performance testing focuses on how individual services and the system as a whole behave under load, rather than on single response times in isolation. As each request spreads across multiple services, small inefficiencies can compound into noticeable latency or failures.
At the service level, performance testing validates how a service handles expected and peak traffic:
- Response times under load, including database and cache interactions.
- Resource usage, such as CPU, memory, and connection pools.
- Behavior when downstream dependencies slow down.
At the system edges, performance testing validates real user impact:
- Latency and throughput at API gateways and ingress points.
- End-to-end request paths for critical user-facing flows.
- Saturation and queuing behavior during traffic spikes.
Together, these tests ensure that locally acceptable performance does not degrade into system-wide instability.
Resiliency Testing: Validating Failure Handling and Recovery
One key aspect of testing is understanding how your system behaves when something goes wrong. Resiliency testing does exactly that: it validates the system's behavior in the event of an issue. Instead of assuming that dependencies are always available and fast, you deliberately introduce failures to observe how services degrade and recover. Chaos checks take this a step further by validating these behaviors under controlled, yet realistic, disruptions.
You measure resiliency to understand whether failures are contained or amplified. Without measurement, retries, timeouts, and circuit breakers may be present in the configuration but fail to behave as intended under real conditions.
Key aspects to measure include:
- Timeout Behavior: Confirms that services fail fast instead of waiting indefinitely on slow dependencies.
- Retry Policies: Ensures that retries are bounded and do not create traffic storms or cascading failures.
- Circuit Breaker Behavior: You verify that breakers trip at the right thresholds and recover gracefully.
- Graceful Degradation: Validates that partial functionality remains available when dependencies are unavailable.
- Recovery Time: The time it takes for services to return to a healthy state after failures are resolved.
Security Testing Across Microservices APIs and Trust Boundaries
Security testing in microservices focuses on testing trust boundaries rather than individual endpoints. Each service exposes APIs, exchanges tokens, and makes authorization decisions, which collectively expand the attack surface. Security testing ensures that these boundaries behave correctly under both expected and adversarial conditions.
You test security to confirm that access controls are consistently enforced and that internal service communication does not rely on implicit trust. A single misconfigured service in microservices can become a lateral movement path across the system.
Observability in Microservices Testing: Making Failures Explainable
Observability is a critical part of any distributed system testing strategy, especially in microservices environments.
While testing, every error you see is usually a symptom, not the cause. Without observability, debugging becomes guesswork, which is why many teams find microservice testing hard to debug. Observability helps teams understand system behavior during testing by connecting logs, metrics, and traces to the root cause of failures.
To make test failures actionable, you should treat observability as part of the testing strategy. Test traffic should behave like production traffic from an observability perspective, carrying context across service boundaries and emitting signals that allow you to reconstruct what happened. Effective test failure triage depends on a small set of disciplined practices:
- Distributed Tracing for Integration and End-to-End Failures: Integration and end-to-end tests fail primarily due to timing issues or assertion failures and service-level outages. With distributed tracing, a technique for tracking and visualizing the path of application requests, you can follow a single request or workflow across multiple services, revealing latency-introduction points. In test environments, traces provide the fastest path to understanding why a multi-service flow broke and where the assertion failed.
- Correlation IDs for End-to-End Test Visibility: Every request triggered by a test should carry a correlation ID. The identifier must propagate consistently across HTTP calls, message brokers, and background jobs. When a failure occurs, the correlation ID serves as the primary handle for investigation, enabling logs, traces, and metrics from multiple services to be viewed as a single narrative rather than isolated fragments.
- Logging and Metrics Strategies for Test Debugging: Instead of relying solely on stack traces, logs generated during test execution should capture key decisions and boundary interactions. Including correlation IDs and test context in log fields lets you quickly filter out noise and focus on the behavior that caused the failure.
- Metric Conventions that Distinguish Test Traffic: Metrics should enable separating test-driven load from background activity. Tagging requests with test identifiers enables you to observe latency, error rates, retries, and saturation specifically for test scenarios. This is especially crucial when identifying flaky tests caused by resource contention or backpressure.
Asynchronous workflows amplify the need for these practices. When events are processed later or out of order, failures may surface far from the original trigger. Observability that spans producers, brokers, and consumers is the only reliable way to determine whether a failure was caused by delayed processing or duplicate events.
You may experience intermittent failures, repeated pipeline reruns, slow root cause analysis, and other debugging pain when observability is missing from your testing strategy. When observability is built into testing, failures become explainable and fixable systematically.
Microservices Testing Tools: Recommended Stack by Test Layer
A robust testing strategy for microservices architecture should never rely on a single toolchain. As your team and software evolve, you need to make necessary adjustments to your tools as well. What should not change is the intent behind each tool category.
When evaluating tools, prioritize these principles first:
- The tool must support automation and CI/CD execution without manual intervention.
- The tool should reinforce isolation, fast feedback, and service boundaries rather than encourage system-wide coupling.
- The output must be observable and debuggable through logs, metrics, or traces.
- The tool should integrate cleanly with containers and Kubernetes, even if you do not use them everywhere today.
Recommended Tools
Microservices testing tools offer a range of functionality and test types. With that in mind, below is a category-based view of tooling, with shortlists to help you move from principle to execution.
a) Unit Testing Tools
Unit testing exists to protect development speed and correctness at the service level. With the right tools, you can validate internal logic quickly for quick PR feedback.
- Jest
- JUnit 5
- Pytest
- Go test
b) Component Testing Tools
Mocking alone cannot expose schema mismatches or configuration errors. The right tools in this category will help you run real infrastructure dependencies in isolation, offering you realistic behavior without long-lived environments.
- Testcontainers
- WireMock
- Prism
- LocalStack
c) Contract Testing Tools
Contract testing tools allow services to evolve independently while preserving compatibility at boundaries. Instead of discovering breaking changes in staging or E2E tests, contracts surface them at merge time.
- Spring Cloud Contract
- Postman
- Spectral
d) Integration Test Tools
Rather than relying on shared staging, integration testing tools enable short-lived environments where a small number of services can interact under controlled conditions, reducing contention and environment drift.
- Docker Compose
- Kind
- k3s
- Tilt
- Skaffold
- Debezium
e) End-to-End Testing Tools
End-to-end tools validate that critical user journeys are wired correctly across the system. Their value lies in confidence, not coverage.
- Playwright
- Cypress
- Selenium
f) Observability Tools
Observability tooling turns failing tests into explainable events. Standardized telemetry ensures that traces, logs, and metrics tell a coherent story across services, which is essential when debugging integration and end-to-end failures.
- OpenTelemetry
- Jaeger
- Zipkin
- Prometheus with Grafana
Conclusion: Building a Scalable Microservices Testing Strategy
Microservices do not fail because teams care less about quality. They fail when teams keep applying testing habits that were built for a different architectural model.
In distributed systems, quality depends on where and how confidence is created. Long E2E suites, shared staging bottlenecks, and unstable test data may look like testing coverage on paper, but they often reduce trust in practice. The more complex the system becomes, the more important it is to catch defects close to the change, enforce contracts at service boundaries, validate a limited set of real interactions, and make failures easy to explain through observability.
This is what enables scalable microservices testing without slowing down delivery. It does not try to test everything in one place. It places the right checks at the right layer so teams can ship faster without losing control over reliability.
A well-designed strategy helps teams reduce test flakiness in microservices, improve CI/CD testing efficiency, and enable scalable microservices testing across complex distributed systems.
If your teams are struggling with flaky pipelines, brittle E2E suites, shared environment contention, or slow release validation, the problem is often not effort. It is test strategy design.
How ThinkSys Helps Teams Strengthen Microservices Testing in 30 Days
Teams usually come to ThinkSys when microservices delivery starts slowing down instead of speeding up. PR checks are noisy, E2E suites are bloated, staging is contested, and debugging takes too long because failures span multiple services.
ThinkSys provides microservices testing services and QA for microservices architecture, helping teams strengthen contract validation, test automation, CI/CD pipelines, and observability-driven debugging.
Our role is to help teams rebuild testing confidence without creating more process overhead.
Week 1: Assess architecture, risks, and current bottlenecks
We begin by understanding your service landscape, release model, pipeline pain points, and failure patterns. This includes reviewing where feedback is slow, which dependencies are fragile, where environments create contention, and which test layers are missing or overloaded.
Week 2: Strengthen service-level and contract validation
Next, we help establish stronger service-level checks and contract verification so breaking changes are caught earlier in CI. This usually reduces avoidable downstream failures and improves confidence in pull request validation.
Week 3: Improve integration coverage and environment strategy
In the third phase, we focus on real interaction risks across selected services. We help narrow integration scope, improve test data control, and introduce more isolated validation approaches such as preview or ephemeral environments where needed.
Week 4: Reduce E2E noise and improve observability
In the final phase, we identify the few critical end-to-end journeys that actually deserve release-gate coverage. We also strengthen observability for test triage so failures are easier to trace across services, queues, and dependencies.
The result is a more practical testing model for microservices: faster feedback, clearer ownership, fewer false alarms, and more reliable releases.
Microservices Testing Strategy Checklist for Engineering Teams
Use this checklist to assess whether your microservices testing strategy is structurally sound. Each point represents a distinct control. If you hesitate to check one, that is where operational risk is likely accumulating.
Architecture
- A documented testing portfolio exists across all test levels.
- Each service has a clearly defined quality scope.
- Ownership for every test level is assigned to a specific team.
- E2E scope is intentionally limited to critical journeys.
- Backward compatibility rules are formally defined.
- Service versioning guidelines are documented and enforced.
- Testing policies are aligned with deployment frequency.
Service-Level Testing
- Unit tests cover core business logic and edge cases.
- Component tests validate the service with its real database.
- External adapters are tested with realistic behavior.
- Service-level performance baselines are defined.
- Service startup and health endpoints are validated automatically.
- Code coverage is measured, but not used as the sole quality metric.
Contract Testing
- Service interfaces are defined through executable contracts.
- Contract verification runs automatically in CI.
- Backward compatibility rules are clearly documented.
- Breaking changes require explicit versioning.
- Contracts are stored in a shared, traceable registry.
Integration Testing
- Focused integration tests validate real service interactions.
- Asynchronous message flows are exercised under test.
- Integration scope is limited to a small number of services.
- Failures are attributable to specific service boundaries.
- Retry and timeout configurations are exercised in integration scenarios.
- Failures are diagnosable through correlation identifiers.
CI/CD Execution
- The pull request gate completes quickly.
- Nightly validation runs broader integration coverage.
- Release gates validate critical user journeys.
- Pipeline failures are explainable without manual guesswork.
- Build failure trends are monitored over time.
- Mean time to feedback is measured and optimized.
Observability
- Distributed tracing is enabled in test environments.
- Correlation IDs propagate across service boundaries.
- Logs follow structured conventions.
- Metrics distinguish test traffic from background traffic.
- Failure triage time is tracked and continuously reduced.
Non-Functional Readiness
- Service-level load testing is performed under peak traffic conditions.
- API gateway and ingress performance is measured.
- Timeout behavior is validated under dependency degradation.
- Retry policies are tested to prevent request amplification.
- Circuit breakers are exercised under simulated outages.
- Security scanning runs automatically before release.
How to Use This Checklist to Identify Testing Gaps
- Run this checklist with engineering, QA, and platform leads together.
- Mark each item as green, amber, or red based on its priority.
- Prioritize red items that directly impact deployment confidence.
- Avoid attempting to fix everything simultaneously.

Share This Article:




