Understanding the Kubernetes Architecture
Developed by the tech giant Google, Kubernetes is an open-source platform used as a container orchestration system that aids in automating, managing, and scaling software development. Kubernetes is growing swiftly in the IT infrastructure within the organizations, but why is it happening? To understand that, it is essential to know the traditional method of running applications. In the traditional methods, its impossible to define resource boundaries for any application running on a physical server. This reason led to issues with resource allocation. The situation worsened when the organization needed to run more than one application on a physical server.
In that case, a running application would consume most of the resources whereas the remaining apps may not receive optimum resources, resulting in poor performance. The only solution left was to run a single application on a single physical server, but that was highly expensive and inefficient.
Later came virtualization, where a virtual machine is created which runs multiple applications on a single physical server. Since its inception, VMs have drastically reduced the usage of traditional methods and saved a lot of resources and efforts of the users.
Kubernetes is similar to virtualization, where containers are used. These containers are lightweight and come with all the major components of a virtual machine but are portable on clouds. Working on a container requires an entire architecture deployment. This article will explain all about Kubernetes architecture clearly.
What is a Container Orchestration System?
A container orchestration system helps in orchestrating major container management tasks. Powered by a containerization tool that handles the lifecycle of a container, the container orchestration system can help in tasks like deployment of a container, creation, and even termination of a container. A container orchestration system is beneficial for the organization as it helps manage the complexities that containers bring with them. Apart from that, this system enhances the overall security of containerized applications by automating several tasks, reducing the probability of human errors.
The container orchestration system is highly beneficial when there are legions of containers distributed across several systems. Such a situation makes managing these containers highly complicated from the Docker command line. With a container orchestration tool, all the container clusters in the environment can be handled as a single unit, making it feasible to manage. All the tasks including starting, running, and termination of numerous containers can be done through a container orchestration system.
What is Kubernetes Architecture?
A Kubernetes architecture is a cluster used for container orchestration. Each cluster contains a minimum of one control plane and nodes. In a cluster, a control plane is responsible for managing the cluster, shutdown, and scheduling of compute nodes depending on their configuration and exposing the API. A node can be a physical or virtual machine with a Linux environment that runs pods.
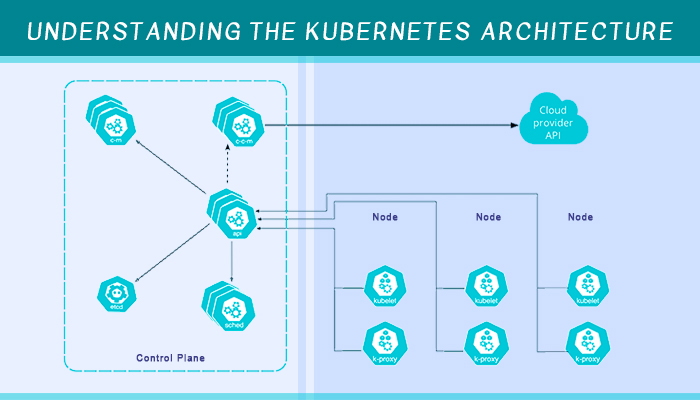
1. Control Plane:
The control plane can be considered as the brain of the entire Kubernetes architecture cluster as it is the one that directly controls it. Additionally, it keeps a data record of the configurations added along with the Kubernetes object states. The control plane has three primary components: kube-scheduler, kube-apiserver, and kube-controller-manager. These all collaboratively ensure that the control plane is performing as it should. Moreover, they can either have a single master node or can be replicated to several master nodes. The replication of these components is done to attain their high availability in case of any fault.
Components of Control Plane:
The Control plane is an essential part of Kubernetes architecture. As stated before, it comprises of several different components, and all of them are explained below.
- Scheduler: Also known as kube-scheduler, it keeps an eye on any new requests received from the API server. Moreover, it analyses the node qualities, ranks them, and deploys the pods depending on the suitability of the node. Any request received from the API server will be allocated to the healthiest node. However, if there are no healthy or suitable nodes, the pods are put on hold until any suitable node is available.
- API Server: The API server is the communication center of the control plane and the only part of the plane where the user can interact directly, ensuring that the data is stored in the cluster as per the service detail agreement. User interfaces and external communications pass to the API server. It also receives the REST requests to pods, controllers, and services regarding any modification.
- Controller Manager: As the name suggests, the controller manager performs different controller processes in the background or manages the controllers. Running a different controller is done to perform regular tasks and to regulate the cluster's shared state. If a service configuration modification is done, the controller manager will identify the change quickly and begin taking the right action for the new state. Node controller, job controller, service account controller, and endpoints controller are among the most widely used types of controller managers.
However, another controller manager handles the existing cloud technologies in the cluster. The cloud controller manager can only function on the controllers specific to a cloud provider and allows the user to link the API of the cloud provider with the cluster.- There are three types of controller managers with cloud provider dependencies. The first is the node controller, which is used to check the cloud provider and define whether the node is deleted in the cloud after being unresponsive or not. The second one is the service controller used to create, delete or update a load balancer. Service controller type can be used to set up routes in the existing cloud infrastructure. Third one is Route controllers: directly affect the communication between containers of different nodes in a Kubernetes architecture.
In simpler terms, the route controller manages the traffic route in the existing Kubernetes infrastructure. However, the route controller is only applicable in Google Compute Engine clusters.
- There are three types of controller managers with cloud provider dependencies. The first is the node controller, which is used to check the cloud provider and define whether the node is deleted in the cloud after being unresponsive or not. The second one is the service controller used to create, delete or update a load balancer. Service controller type can be used to set up routes in the existing cloud infrastructure. Third one is Route controllers: directly affect the communication between containers of different nodes in a Kubernetes architecture.
2. Key-Value Store:
Also known as etcd, the Key-Value Store is used by Kubernetes as its database to keep a backup of the entire cluster data including configurations and states. As the etcd is accessed through the API server, it becomes consistent and accessible for the users. With the ease of access, the key-value store can be configured externally or even a part of the control plane.
Essential Components of Kubernetes Cluster Architecture:
The control plane manages the cluster nodes responsible for running the containers. Every node runs a container runtime engine and acts as an agent to communicate with the primary Kubernetes controller. In addition, other components for service discovery, monitoring, and logging are also done by these nodes. Being directly related to the control plane, knowing about the components of Kubernetes architecture is crucial.
1. Nodes:
Nodes can be defined as either physical servers or virtual machines where Pods are places for execution in the future. Every cluster architecture comes with a minimum of one compute node, but there can be multiple nodes, and it varies with the capacity needs of the architecture. If a cluster capacity is scaled, it is necessary to orchestrate and schedule pods to run on nodes. Making it simpler, nodes are the primary workers that connect several resources including storage, networking, and computing in the architecture. Nodes are classified into two different types: Master and Worker Nodes.
- Master Nodes: A master node is entirely made up of control plane binaries responsible for control plane components. In most cases, a cluster will have over three master nodes so that it can reach the goal of high availability.
- Worker Node: A worker node will have components like kube-proxy, kubelet, and container runtime which lets it run the desired containers. With that in mind, the control plane is entirely responsible for managing this type of node.
Components of Kubernetes Nodes:
- Kube-proxy: Kube-proxy or the network proxy is responsible for maintaining communication between pods and network sessions inside or outside the cluster on each node. It also uses the operating system packet filtering if it is available in the nodes. Managing IP translation, network rules, load-balancing on all pods, and routing are among the functions of this node component. Moreover, it makes sure that every pod attains a distinctive IP address and containers in the same pod share the same IP.
- Kubelet: Every container described in PodSpecs should run adequately for the best outcome. Kubelet is an agent present in every node and its primary task is to make sure that these containers are continuously working as they should.
- Container Runtime: Every worker node comes with a container runtime engine used to run the container. This software accomplishes this task and starts or stops the container depending on the deciding factors. Docker, Container Runtime Interface, and containerd are some of the industry-leading container runtime software.
2. Pods
Pods are responsible for encapsulating the application containers, network ID, storage resources, and all the remaining configurations for running the containers. Though they are controlled as a separate application, pods are one or multiple containers that share data and resources.
3. Volume
Another significant component of Kubernetes architecture is the volume applied to the entire pod. Volume is linked to all the containers in the pod and ensures that the data is saved. Moreover, a single pod can have several volumes depending on the pod type. A volume ensures that the data is preserved and can only be eradicated upon elimination of the pod.
4. Deployment:
The deployment controller updates the environment and describes the pod's desired state in the YAML file. It is responsible for updating the current state with the desired state in the deployment file. In short, it is a deployment method for containerized application pods.
5. Service:
Sometimes replicating a controller can kill the existing pod and commence a new set. Moreover, Kubernetes does not claim that a physical pod will remain alive in any such stance. Service depicts a set of pods that lets pods send a necessary request to the service. The great thing is that this does not require keeping track of any physical pod.
6. Namespace:
Environments with multiple teams, projects, and users may need isolation which they can attain from Namespace. A resource quota is allocated to a namespace so that it does not use more than its share of the physical cluster. Moreover, the resources within a namespace should be distinctive, and no namespace can access resources from any other namespace.
7.ConfigMaps and Secrets:
ConfigMaps is used for storing commonly used or non-confidential data in key-value pairs. With this component, you can make your app's portability easier by decoupling configurations specific to an environment from container images. The data can be entire configuration files or small properties. In a Kubernetes architecture, both ConfigMaps and Secrets let the user change configuration without the need for an application build.
Though both of these terms are similar, there are several differences. The foremost one is data encoding, where Secrets uses base64 encoding to store data. Furthermore, Secrets are mostly used for storing passwords, certificates, pull secrets, and other similar data types.
8. StatefulSets:
Deployment of a stateful application in a Kubernetes cluster is tricky due to its replica architecture and fixed Pod name requirement. StatefulSets is a workload API object that can run stateful apps as containers in a Kubernetes cluster. It also handles the deployment of Pods based on an identical container specification. In other words, controllers implement uniqueness properties and run stateful applications in a Kubernetes architecture.
9.Replication Controllers:
A ReplicaSet let you know about the number of times a pod is required in architecture. A replication controller handles the entire system to match the number of pods in a ReplicaSet with the number of working pods in the architecture.
10. Labels and Selectors:
Labels are value pairs linked to objects like pods used to showcase the characteristics or information relevant to the users. These can either be added while objects are created or modified later. Moreover, they can also be used for organizing or selecting subsets of objects. However, many different labels may have the same name, confusing the user while identifying a set of objects. With that in mind, Selectors are used to help group the objects. Set-based and equality-based are the two types of selectors where filtering is done based on a set of values and label keys, respectively.
11. Add-Ons:
Like any other application, add-ons are used in a Kubernetes architecture to extend its functionality. Add-ons are implemented through services and pods, and they implement Kubernetes cluster features. Different types of add-ons can be managed by ReplicationControllers, Deployments, and many others. Some of the popular Kubernetes add-ons are Web UI, cluster-level logging, and DNS.
12. Storage:
A Kubernetes storage is mainly based on Volumes divided into two: persistent and non-persistent. Persistent storage supports different storage models, including cloud services, object storage, and block storage. A Kubernetes storage comes with non-persistent storage by default. Such storages are part of a container in a Pod which is stored in a temporary storage space of the host and will exist along with the pod.
Features of Kubernetes:
Kubernetes is not just an orchestration tool but offers many valuable features. Having five different functionalities of Kubernetes architectures ensures that it becomes an overall package offering several features. Here are all the primary functionalities that you can get with Kubernetes.
Features#1: Rollbacks -
There are stances when the desired changes remain incomplete, which can dramatically impact the end-user's experience. Kubernetes comes with an automated rollback feature that can reverse the changes made. Furthermore, it can also switch the existing pods with new pods and change their configurations.
Features#2: Self-Healing-
Issues can occur at any moment and allowing connections to an unhealthy pod could be catastrophic. Kubernetes constantly keep an eye on the pod's health and ensure that they are working perfectly. In case any container fails to function, it can automatically restart. However, if that does not work, the system will hinder the connection to those pods till the issues are fixed.
Features#3: Load Balancing-
Load balancing is one of the biggest aspects of efficient utilization of resources and keeping the pods stable. By automatically balancing the load among multiple pods, Kubernetes ensures that no pod is overburdened.
Features#4: Bin Packing-
Not just load balancing, but other practices are necessary to keep resource utilization in check. Depending on the CPU configuration and RAM requirements, Kubernetes assigns the containers accordingly so that no resources are wasted during the task.
Features#5: Better Security-
Security is a significant concern before adopting any new technology. If the tech is proven to be secure or brings practices that ensure security, the user's confidence increases drastically. With practices like transport layer security, cluster access to authenticated users, and the ability to define network policies, Kubernetes expands the overall security.
Furthermore, it also addresses security and application, cluster, and network levels. However, certain practices like updating Kubernetes to the latest version, securing the Kubelet, reducing operational risk through Kubernetes native security controls, and securing the configuration of Kubernetes API are some of the practices that will help in extending the security even further.
Use Cases of Kubernetes Architecture:
Use Cases#1: Cloud Migration-
The Lift and Shift method of migration is a renowned way of migrating the application along with all the data to the cloud without any changes or minimal changes. Several organizations use this method for migrating their application to large Kubernetes pods. After they become comfortable with the cloud, they break the large pod into small components to minimize the migration risk while making the most out of the cloud.
Use Cases#2: Serverless Architecture -
Serverless architecture is widely used by organizations to build and deploy a program without obtaining or maintaining physical servers. Here, a third-party server provider will lend a space in their servers to an organization. Even though it is an excellent way for many, the lock-in by such providers may be a deal-breaker for some. On the other hand, Kubernetes architecture lets the organization build a serverless platform with the existing infrastructure.
Use Cases#3: Continuous Delivery -
DevOps is all about continuous integration/ continuous delivery. Kubernetes architecture can automate the deployment when a developer builds the code using the continuous integration server, making Kubernetes a significant part of the DevOps pipeline.
Use Cases#4: Multi-Cloud Deployment -
Cloud deployments come in different types, including private, public, hybrid, and on-premise. When the data from different applications move to different cloud environments, it is complicated for the organizations to manage the resource distribution. With the automated distribution of resources in a multi-cloud environment, Kubernetes architecture makes it feasible for organizations to manage resources efficiently.
Conclusion:
Without a doubt, Kubernetes architecture is a scalable and robust orchestration tool. This was all about the Kubernetes architecture, its components, and the features that it brings. Since its inception by Google, it has reduced resource wastage and burden on the physical servers by virtualization and orchestration. Being designed specifically for security, scaling, and high availability, this tool has fulfilled the goals and continues to do so.
Suppose you want to migrate to cloud technologies or enhance your current cloud infrastructure using Kubernetes. In that case, all you have to do is connect with ThinkSys Inc. Migration to the cloud is not just complicated but can be expensive if done incorrectly. With the assistance from ThinkSys Inc, you will get the best migration and save your budget. Our professionals will evaluate the stability of your existing applications before migrating to Kubernetes architecture.
Frequently Asked Questions:
Q1: Who should use Kubernetes?
Q2: What are the problems solved by Kubernetes Architecture?
Q3: Is Kubernetes complicated to use? If so, how to use this to manage operations?
Q4: Are there any alternatives to Kubernetes?
Q5: How to migrate to cloud technologies or enhance your current cloud infrastructure using Kubernetes?
Q6: How is Kubernetes changing microservices architectures?
Q7: What does one need on-premises to run Kubernetes architecture?
1.A minimum of one server, but the recommended number is at least three for optimum performance of control plane components and worker nodes.
2. Having a separate server for the master components.
3. SSD.
4. Dedicated load balancer node.
5. Building services like scalable networking, persistent storage, etcd, ingress, and high-availability master nodes.
Share This Article:







